Enregistrer le modèle ML pour une utilisation future
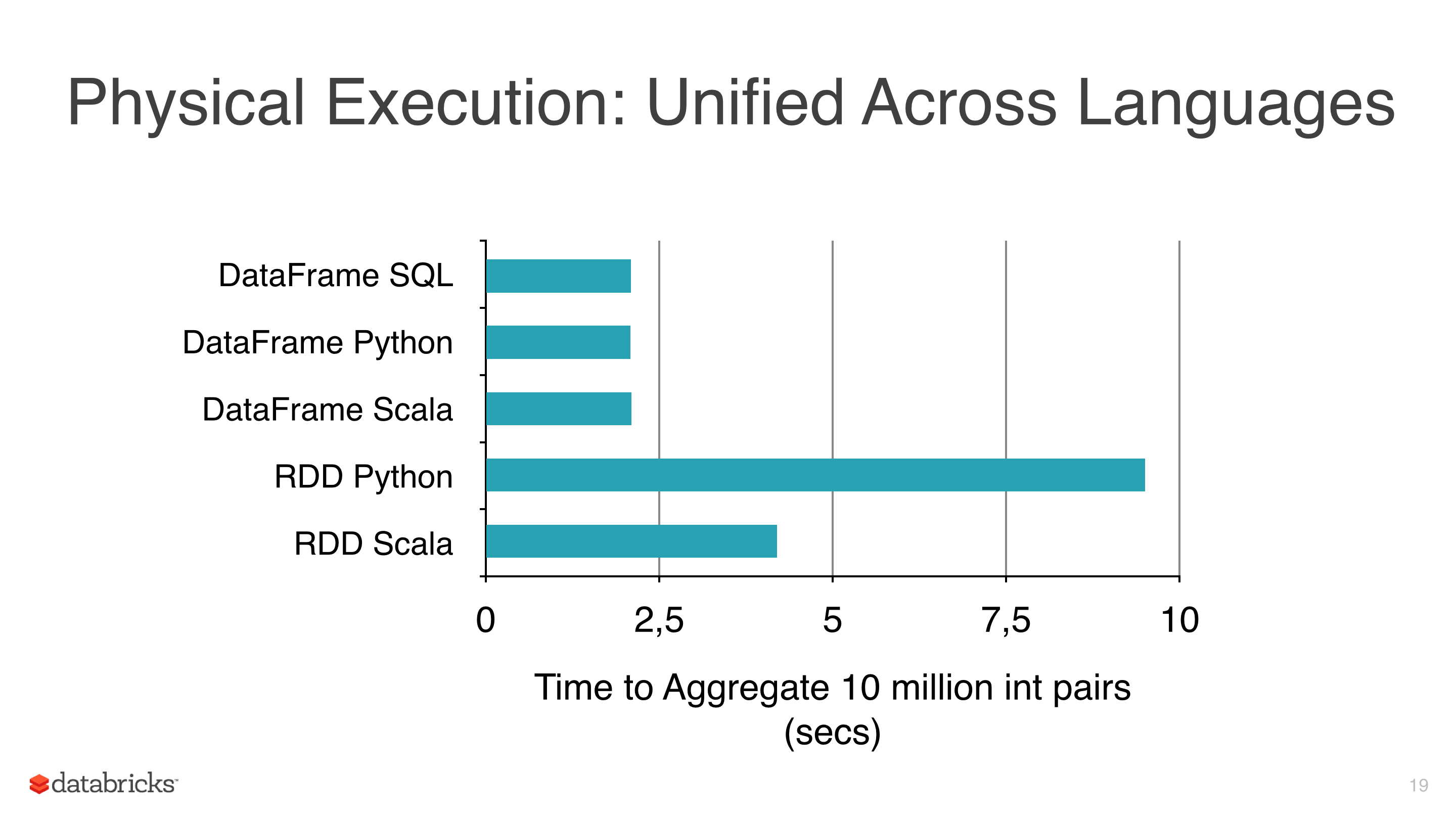
J'appliquais des algorithmes d'apprentissage automatique comme la régression linéaire, la régression logistique et Naive Bayes à certaines données, mais j'essayais d'éviter d'utiliser des RDD et de commencer à utiliser des DataFrames parce que les RDD sont plus lents que les Dataframes sous pyspark ( voir photo 1).
L'autre raison pour laquelle j'utilise DataFrames est que la bibliothèque ml a une classe très utile pour régler les modèles qui est CrossValidator cette classe retourne un modèle après l'avoir adapté, évidemment cette méthode doit tester plusieurs scénarios, et après cela retourne un modèle ajusté (avec les meilleures combinaisons de paramètres).
Le cluster que j'utilise n'est pas si grand et les données sont assez grandes et certains ajustements prennent des heures, donc je veux enregistrer ces modèles pour les réutiliser plus tard, mais je ne sais pas comment, y a-t-il quelque chose que j'ignore?
Remarques:
- Les classes de modèle de mllib ont une méthode de sauvegarde (c'est-à-dire NaiveBayes ), mais mllib n'a pas CrossValidator et n'utilise pas de RDD, donc je l'évite avec préméditation.
- La version actuelle est spark 1.5.1.
Spark 2.0.0+
À première vue, tous les Transformers et Estimators implémentent MLWritable avec l'interface suivante:
def write: MLWriter
def save(path: String): Unit
et MLReadable avec l'interface suivante
def read: MLReader[T]
def load(path: String): T
Cela signifie que vous pouvez utiliser la méthode save pour écrire le modèle sur le disque, par exemple
import org.Apache.spark.ml.PipelineModel
val model: PipelineModel
model.save("/path/to/model")
et lisez-le plus tard:
val reloadedModel: PipelineModel = PipelineModel.load("/path/to/model")
Des méthodes équivalentes sont également implémentées dans PySpark avec MLWritable / JavaMLWritable et MLReadable / JavaMLReadable respectivement:
from pyspark.ml import Pipeline, PipelineModel
model = Pipeline(...).fit(df)
model.save("/path/to/model")
reloaded_model = PipelineModel.load("/path/to/model")
SparkR fournit write.ml / read.ml fonctions, mais à ce jour, elles ne sont pas compatibles avec les autres langues prises en charge - SPARK-15572 .
Notez que la classe du chargeur doit correspondre à la classe du PipelineStage stocké. Par exemple, si vous avez enregistré LogisticRegressionModel, vous devez utiliser LogisticRegressionModel.load ne pas LogisticRegression.load.
Si vous utilisez Spark <= 1.6.0 et rencontrez des problèmes avec l'enregistrement du modèle, je suggère de changer de version.
En plus des méthodes spécifiques Spark, il existe un nombre croissant de bibliothèques conçues pour enregistrer et charger les modèles Spark ML en utilisant Spark Voir par exemple Comment servir un modèle Spark MLlib? .
Étincelle> = 1,6
Depuis Spark 1.6 il est possible d'enregistrer vos modèles en utilisant la méthode save. Parce que presque chaque model implémente l'interface MLWritable . Pour exemple, LinearRegressionModel l'a, et il est donc possible d'enregistrer votre modèle sur le chemin souhaité en l'utilisant.
Étincelle <1,6
Je crois que vous faites des hypothèses incorrectes ici.
Certaines opérations sur un DataFrames peuvent être optimisées et cela se traduit par des performances améliorées par rapport à un simple RDDs. DataFrames fournit une mise en cache efficace et l'API SQLish est sans doute plus facile à comprendre que l'API RDD.
Les pipelines ML sont extrêmement utiles et des outils comme le validateur croisé ou différents évaluateurs sont tout simplement indispensables dans n'importe quel pipeline de machine et même si rien de ce qui précède n'est particulièrement difficile à mettre en œuvre au-dessus de l'API MLlib de bas niveau, il est préférable d'avoir prêt à utilisation, solution universelle et relativement bien testée.
Jusqu'ici tout va bien, mais il y a quelques problèmes:
- pour autant que je sache, des opérations simples sur un
DataFramescommeselectouwithColumnaffichent des performances similaires à ses équivalents RDD commemap, - dans certains cas, l'augmentation du nombre de colonnes dans un pipeline typique peut en fait dégrader les performances par rapport à des transformations de bas niveau bien réglées. Vous pouvez bien sûr ajouter des transformateurs drop-column sur le chemin pour corriger cela,
- de nombreux algorithmes ML, dont
ml.classification.NaiveBayessont simplement des wrappers autour de sonmllibAPI, - Les algorithmes PySpark ML/MLlib délèguent le traitement réel à ses homologues Scala,
- le dernier mais non le moindre RDD est toujours là, même s'il est bien caché derrière DataFrame API
Je crois qu'en fin de compte, ce que vous obtenez en utilisant ML sur MLLib est une API de haut niveau assez élégante. Une chose que vous pouvez faire est de combiner les deux pour créer un pipeline personnalisé en plusieurs étapes:
- utiliser ML pour charger, nettoyer et transformer des données,
- extraire les données requises (voir par exemple la méthode extractLabeledPoints ) et passer à l'algorithme
MLLib, - ajouter une validation/évaluation croisée personnalisée
- enregistrer le modèle
MLLiben utilisant la méthode de votre choix (modèle Spark ou PMML )
Ce n'est pas une solution optimale, mais c'est la meilleure à laquelle je peux penser étant donné une API actuelle.
Il semble que la fonctionnalité API pour enregistrer un modèle ne soit pas implémentée à ce jour (voir Spark issue tracker SPARK-6725 ).
Une alternative a été publiée ( Comment enregistrer des modèles de ML Pipeline vers S3 ou HDFS? ) qui implique simplement de sérialiser le modèle, mais est une approche Java. J'espère que dans PySpark, vous pourriez faire quelque chose de similaire, c'est-à-dire décaper le modèle pour écrire sur le disque.