Attendez la fin des travaux d'arrière-plan bash dans le script
Pour maximiser l'utilisation du CPU (je lance des choses sur un Debian Lenny dans EC2), j'ai un script simple pour lancer des jobs en parallèle:
#!/bin/bash
for i in Apache-200901*.log; do echo "Processing $i ..."; do_something_important; done &
for i in Apache-200902*.log; do echo "Processing $i ..."; do_something_important; done &
for i in Apache-200903*.log; do echo "Processing $i ..."; do_something_important; done &
for i in Apache-200904*.log; do echo "Processing $i ..."; do_something_important; done &
...
Je suis assez satisfait de cette solution de travail, mais je ne pouvais pas comprendre comment écrire du code supplémentaire qui ne s'exécutait qu'une fois toutes les boucles terminées.
Existe-t-il un moyen de contrôler cela?
Il y a une commande intégrée bash pour cela.
wait [n ...]
Wait for each specified process and return its termination sta‐
tus. Each n may be a process ID or a job specification; if a
job spec is given, all processes in that job’s pipeline are
waited for. If n is not given, all currently active child pro‐
cesses are waited for, and the return status is zero. If n
specifies a non-existent process or job, the return status is
127. Otherwise, the return status is the exit status of the
last process or job waited for.
L'utilisation de GNU Parallel rendra votre script encore plus court et peut-être plus efficace:
parallel 'echo "Processing "{}" ..."; do_something_important {}' ::: Apache-*.log
Cela exécutera un travail par cœur de processeur et continuera de le faire jusqu'à ce que tous les fichiers soient traités.
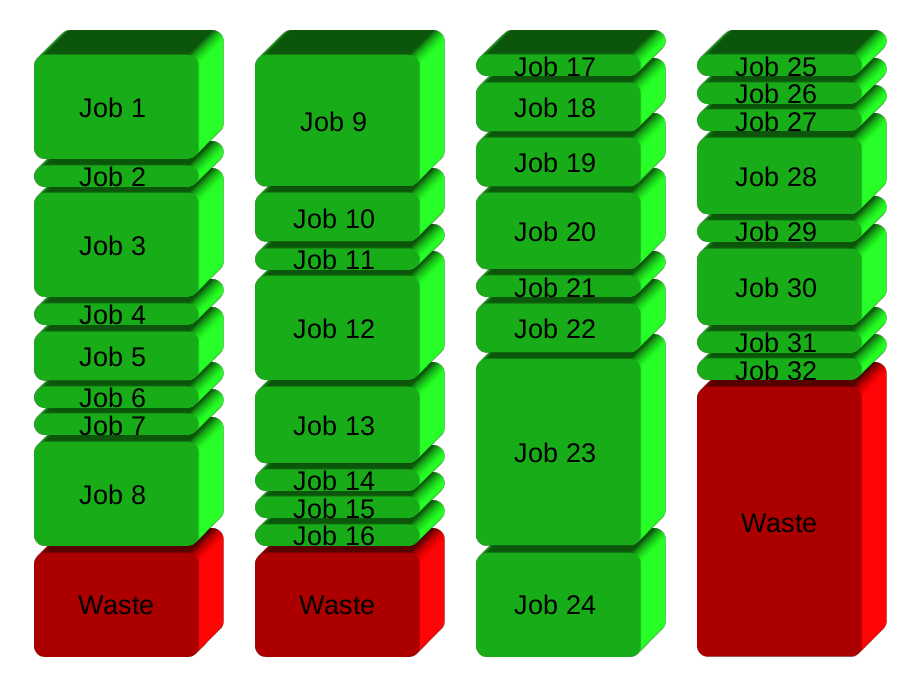
Votre solution divisera essentiellement les travaux en groupes avant de s'exécuter. Voici 32 emplois en 4 groupes:
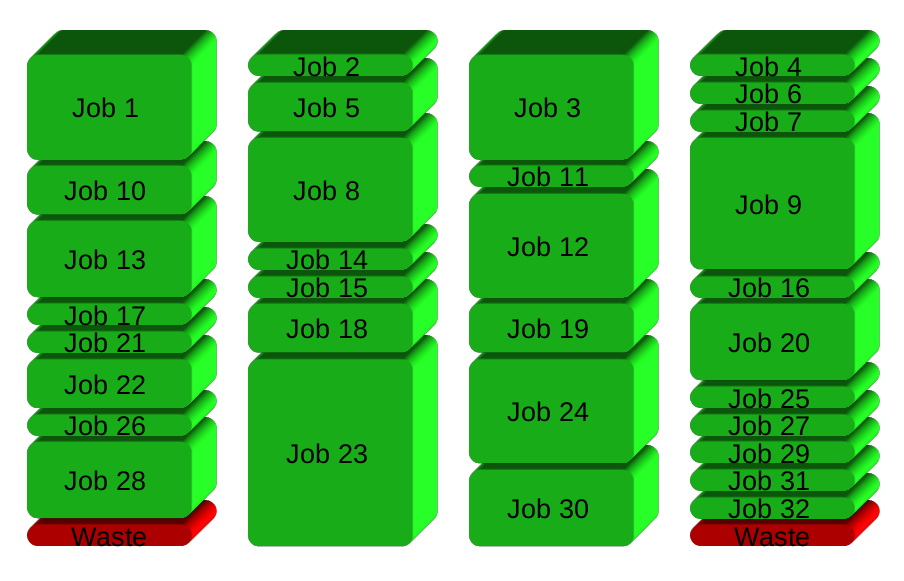
GNU Parallel génère à la place un nouveau processus à la fin - en maintenant les CPU actifs et en économisant ainsi du temps:
Pour apprendre plus:
- Regardez la vidéo d'introduction pour une introduction rapide: https://www.youtube.com/playlist?list=PL284C9FF2488BC6D1
- Parcourez le didacticiel (man parallel_tutorial). Votre ligne de commande vous aimera pour cela.
J'ai dû le faire récemment et je me suis retrouvé avec la solution suivante:
while true; do
wait -n || {
code="$?"
([[ $code = "127" ]] && exit 0 || exit "$code")
break
}
done;
Voici comment ça fonctionne:
wait -n se ferme dès que l'un des (potentiellement nombreux) travaux d'arrière-plan se ferme. Il prend toujours la valeur true et la boucle continue jusqu'à ce que:
- Code de sortie
127: la dernière tâche d'arrière-plan s'est terminée avec succès. Dans ce cas, nous ignorons le code de sortie et quittons le sous-shell avec le code 0. - L'un des travaux en arrière-plan a échoué. Nous venons de quitter le sous-shell avec ce code de sortie.
Avec set -e, cela garantira que le script se terminera tôt et passera par le code de sortie de tout travail d'arrière-plan ayant échoué.
Voici ma solution brute:
function run_task {
cmd=$1
output=$2
concurency=$3
if [ -f ${output}.done ]; then
# experiment already run
echo "Command already run: $cmd. Found output $output"
return
fi
count=`jobs -p | wc -l`
echo "New active task #$count: $cmd > $output"
$cmd > $output && touch $output.done &
stop=$(($count >= $concurency))
while [ $stop -eq 1 ]; do
echo "Waiting for $count worker threads..."
sleep 1
count=`jobs -p | wc -l`
stop=$(($count > $concurency))
done
}
L'idée est d'utiliser des "jobs" pour voir combien d'enfants sont actifs en arrière-plan et d'attendre que ce nombre baisse (un enfant quitte). Une fois qu'un enfant existe, la tâche suivante peut être lancée.
Comme vous pouvez le voir, il y a aussi un peu de logique supplémentaire pour éviter d'exécuter plusieurs fois les mêmes expériences/commandes. Il fait le travail pour moi. Cependant, cette logique pourrait être ignorée ou encore améliorée (par exemple, vérifier les horodatages de création de fichiers, les paramètres d'entrée, etc.).