Comment remplacer toutes les chaînes d'un fichier commençant par un préfixe
Exemple:
1:20 2:25 3:0.432 2:-17 10:12
Je veux remplacer toutes les chaînes qui commencent par 2: à 2:0.
Sortie:
1:20 2:0 3:0.432 2:0 10:12
Utiliser sed:
sed -E 's/((^| )2:)[^ ]*/\10/g' in > out
En outre, comme inspiré par réponse de souravc , s'il y a non une chance de sous-chaîne 2: après le début d'une chaîne non contenant une sous-chaîne 2: principale (par exemple, il y a non une chance d'une chaîne 1:202:25, que la commande abrégée suivante remplacerait en 1:202:0), la commande pourrait être abrégée à ceci:
sed -E 's/2:[^ ]*/2:0/g' in > out
Décomposition de la commande n ° 1/n ° 2 :
-E: permet àsedd'interpréter le motif en tant que motif ERE (Extended Regular Expression);> out: redirigestdoutversout;
sed décomposition de la commande n ° 1 :
s: affirme effectuer une substitution/: lance le motif(: démarre le groupe de capture(: commence à regrouper les chaînes autorisées^: correspond au début de la ligne|: sépare la deuxième chaîne autorisée- : correspond à un personnage
): arrête de grouper les chaînes autorisées2: correspond à un caractère2:: correspond à un caractère:): arrête le groupe de capture[^ ]*: correspond à un nombre quelconque de caractères non/: arrête le motif/démarre la chaîne de remplacement\1: backreference remplacé par le premier groupe de capture0: ajoute un caractère0/: arrête la chaîne de remplacement/démarre les drapeaux de modèleg: affirme effectuer la substitution de manière globale, c'est-à-dire substituer chaque occurrence du motif dans la ligne
sed panne de la commande n ° 2 :
s: affirme effectuer une substitution/: lance le motif2: correspond à un caractère2:: correspond à un caractère:[^ ]*: correspond à un nombre quelconque de caractères non/: arrête le motif/démarre la chaîne de remplacement2:0: ajoute une chaîne2:0/: arrête la chaîne de remplacement/démarre les drapeaux de modèleg: affirme effectuer la substitution de manière globale, c'est-à-dire substituer chaque occurrence du motif dans la ligne
Cette doublure utilisant sed
sed -i.bkp 's/2:\([0-9]*\)\|2:\(-\)\([0-9]*\)/2:0/g' input_file
will en ligne remplacera globalement dans input_file conservera un fichier de sauvegarde nommé input_file.bkp dans le même répertoire.
Cela peut être raccourci davantage en utilisant des expressions rationnelles étendues comme suggéré par kos, comme
sed -ri.bkp 's/2:\-?[0-9]*/2:0/g' input_file
Je voudrais utiliser une boucle de base awk:
$ awk '{for (i=1; i<=NF; i++) $i~/^2:/ && $i="2:0"}1' file
1:20 2:0 3:0.432 2:0 10:12
Cela parcourt tous les champs. Chaque fois que l'un d'eux commence par 2:, il le remplace entièrement par 2:0. Enfin, 1 signifie True, afin que toute la ligne soit imprimée.
Utiliser python:
#!/usr/bin/env python2
import re
with open('test_dir/unix_se.txt') as f:
for line in f:
print re.sub(r'(?:(?<=(?: 2:))|(?<=(?:^2:)))[^ ]*', '0', line).rstrip()
Ici, nous avons utilisé la fonction re.sub du module re.
re.sub()a le motifsub(pattern, repl, string, count=0, flags=0)Comme nous n'utiliserons plus les valeurs à l'intérieur du groupe, nous avons utilisé la notation de groupe non capturant
(?:)(?:(?<=(?: 2:))|(?<=(?:^2:)))utilise l'apparence positive zéro derrière pour faire correspondre2:au début ou suivi d'un espace.[^ ]*fera correspondre zéro ou plusieurs caractères avant l'espace, après2:, puis les remplacera par0.
Voici un exemple:
Contribution:
2:456 1:20 2:25 3:0.432 2:-17 10:12
1:20 2:25 3:0.432 2:-17 10:12 2:543 2:-78
Sortie:
2:0 1:20 2:0 3:0.432 2:0 10:12
1:20 2:0 3:0.432 2:0 10:12 2:0 2:0
Merci @kos pour la version sed:
Quelques petites modifications pour la manière Perl:
Perl -pe 's/((^|\s)2:)[^\s]*/${1}0/g' testdata
Ecrivez en retour avec:
Perl -i -pe 's/((^|\s)2:)[^\s]*/${1}0/g' testdata
Explication:
((^|\s)2:)[^\s]*
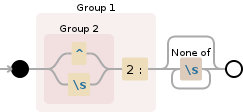
1er groupe de capture
((^|\s)2:)- 2ème groupe de capture
(^|\s) 1ère alternative:
^^assert la position au début de la chaîne2ème alternative:
\s\scorrespond à n'importe quel caractère blanc[\r\n\t\f ]
2:correspond aux caractères2:littéralement- 2ème groupe de capture
[^\s]*correspond à un seul caractère non présent dans la liste ci-dessousQuantificateur:
*Entre zéro et un nombre illimité de fois, autant de fois que possible, redonner au besoin [gourmand]\scorrespond à n'importe quel caractère blanc[\r\n\t\f ]
Ou avec un regard positif , merci @steeldriver
Perl -pe 's/(?<=2:)\S*/0/g' testdata
Explication
(?<=2:)\S*
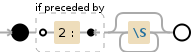
(?<=2:)Lookbehind positif - Affirme que les expressions rationnelles ci-dessous peuvent être appariées2:correspond aux caractères2: littéralement\S*correspond à tout caractère non blanc[^\r\n\t\f ]Quantificateur:
*Entre zéro et un nombre illimité de fois, autant de fois que possible, redonner au besoin [gourmand]