Quel modèle de conception convient le mieux à la journalisation?
Je devrais enregistrer certains événements dans un programme, mais pour autant que je sache, il serait préférable de garder le code de journalisation en dehors du programme car il ne s'agit pas de la fonctionnalité réelle du programme. Alors, pouvez-vous me dire si je dois le garder complètement hors du code et utiliser uniquement des observateurs et des écouteurs pour enregistrer les événements? Ou je peux ajouter une ligne de code comme celle-ci partout où je dois enregistrer quelque chose:
MyGloriousLogger.getXXXLogger().Log(LogPlace, new LogObject(z1, z2, z3, z4, ..., z99));
Dois-je faire une erreur en utilisant le modèle de conception Observer? J'ai besoin d'un autre modèle de conception? Ou devrais-je arrêter de penser aux modèles de conception?
PS1. Si je veux me connecter en utilisant uniquement des auditeurs et des observateurs, je devrai certainement ajouter et améliorer les observateurs et les auditeurs du programme.
PS2. Je sais certainement qu'il existe différentes bibliothèques pour se connecter Java et j'utilise Java.utils.logging mais j'ai besoin d'un wrapper pour enregistrer mes objets spéciaux.
Logging est généralement implémenté avec le modèle de chaîne de responsabilité . Bien sûr, vous pouvez (et je le ferais) combiner cela avec un Facade . Je n'utiliserais vraiment pas d'écouteur (s) ou d'observateur (s) moi-même.
Utilisez Programmation orientée aspect qui utilise les conseils Après, Avant et Autour des méthodes. Là, selon vos besoins, vous pouvez ajouter des journaux avant le démarrage de l'API, après ou à certaines conditions et également séparer votre code principal du code de journalisation.
Eh bien, Observer me semble impropre. En outre, lancer des appels de l'enregistreur "où vous en avez besoin" brisera votre code et violera le SRP.
Vous pourriez - par exemple - être intéressé par AOP pour cela, afin que vous puissiez attacher des appels d'enregistreur via des annotations de méthode.
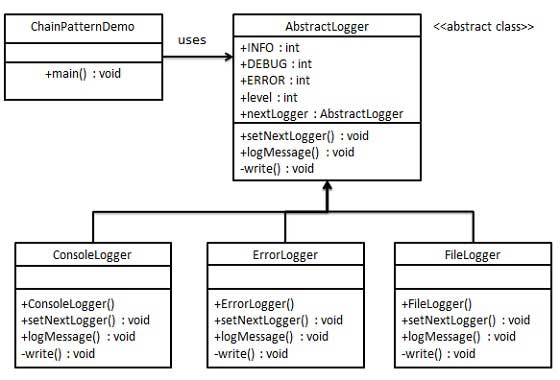
La chaîne de responsabilité semble être un bon modèle lorsque votre sortie peut atterrir à plusieurs endroits. Dans l'UML, vous avez un enregistreur différent qui dirige vers la console, l'autre vers errorFile et le 3ème simplement enregistreur d'informations.
Habituellement, j'ai vu que logLevels sont différents mais le fichier de journalisation est le même.
Je ne vois pas le modèle d'observateur aussi mauvais pour la journalisation car il dissocie votre code de journalisation du code d'application. Ce qui est une bonne pratique, la migration vers différents mécanismes de journalisation est facile de cette façon. Chaque fois que vous souhaitez vous connecter, déclenchez un événement et l'auditeur approprié recevra l'événement et l'enregistrera. Il devrait y avoir un objet singleton intermédiaire qui contient la liste de tous les registres.
De cette façon, je vois que nous pouvons découpler notre code de journalisation du code d'application.