Comment utiliser un cursor.forEach () dans MongoDB avec Node.js?
Ma base de données contient une énorme collection de documents et je me demande comment puis-je parcourir tous les documents et les mettre à jour, chaque document ayant une valeur différente.
La réponse dépend du pilote que vous utilisez. Tous les pilotes MongoDB que je connais ont cursor.forEach() implémenté d'une manière ou d'une autre.
Voici quelques exemples:
node-mongodb-native
collection.find(query).forEach(function(doc) {
// handle
}, function(err) {
// done or error
});
mongojs
db.collection.find(query).forEach(function(err, doc) {
// handle
});
moine
collection.find(query, { stream: true })
.each(function(doc){
// handle doc
})
.error(function(err){
// handle error
})
.success(function(){
// final callback
});
mangouste
collection.find(query).stream()
.on('data', function(doc){
// handle doc
})
.on('error', function(err){
// handle error
})
.on('end', function(){
// final callback
});
Mise à jour de documents à l'intérieur de .forEach rappeler
Le seul problème avec la mise à jour des documents à l'intérieur de .forEach _ callback signifie que vous ne savez pas quand tous les documents sont mis à jour.
Pour résoudre ce problème, vous devez utiliser une solution de flux de contrôle asynchrone. Voici quelques options:
- asynchrone
- promesses ( when.js , bluebird )
Voici un exemple d'utilisation de async, en utilisant sa fonction queue :
var q = async.queue(function (doc, callback) {
// code for your update
collection.update({
_id: doc._id
}, {
$set: {hi: 'there'}
}, {
w: 1
}, callback);
}, Infinity);
var cursor = collection.find(query);
cursor.each(function(err, doc) {
if (err) throw err;
if (doc) q.Push(doc); // dispatching doc to async.queue
});
q.drain = function() {
if (cursor.isClosed()) {
console.log('all items have been processed');
db.close();
}
}
En utilisant le pilote mongodb et le NodeJS moderne avec async/wait, une bonne solution consiste à utiliser next() :
const collection = db.collection('things')
const cursor = collection.find({
bla: 42 // find all things where bla is 42
});
let document;
while ((document = await cursor.next())) {
await collection.findOneAndUpdate({
_id: document._id
}, {
$set: {
blu: 43
}
});
}
Ainsi, un seul document à la fois est requis en mémoire, par exemple, par exemple. la réponse acceptée, où de nombreux documents sont aspirés en mémoire, avant que le traitement des documents ne commence. Dans les cas de "grandes collections" (selon la question), cela peut être important.
Si les documents sont volumineux, cela peut être encore amélioré en utilisant projection , de sorte que seuls les champs de documents requis soient extraits de la base de données.
var MongoClient = require('mongodb').MongoClient,
assert = require('assert');
MongoClient.connect('mongodb://localhost:27017/crunchbase', function(err, db) {
assert.equal(err, null);
console.log("Successfully connected to MongoDB.");
var query = {
"category_code": "biotech"
};
db.collection('companies').find(query).toArray(function(err, docs) {
assert.equal(err, null);
assert.notEqual(docs.length, 0);
docs.forEach(function(doc) {
console.log(doc.name + " is a " + doc.category_code + " company.");
});
db.close();
});
});
Notez que l'appel .toArray Effectue l'application pour extraire l'intégralité du jeu de données.
var MongoClient = require('mongodb').MongoClient,
assert = require('assert');
MongoClient.connect('mongodb://localhost:27017/crunchbase', function(err, db) {
assert.equal(err, null);
console.log("Successfully connected to MongoDB.");
var query = {
"category_code": "biotech"
};
var cursor = db.collection('companies').find(query);
function(doc) {
cursor.forEach(
console.log(doc.name + " is a " + doc.category_code + " company.");
},
function(err) {
assert.equal(err, null);
return db.close();
}
);
});
Notez que le curseur renvoyé par la find() est attribué à var cursor. Avec cette approche, au lieu de récupérer toutes les données dans Memort et de consommer des données à la fois, nous les transmettons en continu à notre application. find() peut créer un curseur immédiatement car il ne demande pas à la base de données tant que nous n'essayons pas d'utiliser certains des documents fournis. Le but de cursor est de décrire notre requête. Le deuxième paramètre de cursor.forEach Indique ce qu'il faut faire lorsque le pilote est épuisé ou qu'une erreur survient.
Dans la version initiale du code ci-dessus, c'était toArray() qui a forcé l'appel de la base de données. Cela signifiait que nous avions besoin de TOUS les documents et que nous voulions qu'ils soient dans un array.
De plus, MongoDB renvoie les données au format batch. L'image ci-dessous montre les requêtes des curseurs (de l'application) à MongoDB
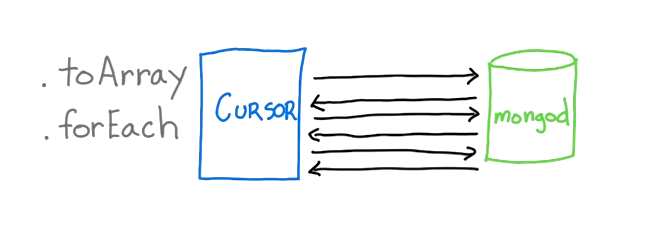
forEach est meilleur que toArray car nous pouvons traiter des documents lorsqu'ils entrent jusqu'à la fin. Comparez-le avec toArray - où nous attendons TOUT les documents à récupérer et le tableau entier est construit . Cela signifie que nous ne tirons aucun avantage du fait que le pilote et le système de base de données travaillent ensemble pour regrouper les résultats de votre application. Le traitement par lots est conçu pour fournir une efficacité en termes de surcharge de mémoire et de temps d'exécution. Profitez-en, si vous le pouvez dans votre application .
La réponse de Leonid c'est bien, mais je veux insister sur l'importance d'utiliser async/promesses et donner une solution différente avec un exemple de promesses.
La solution la plus simple à ce problème consiste à mettre en boucle chaque document et à appeler une mise à jour. Habituellement, vous vous n'avez pas besoin de fermer la connexion à la base de données après chaque demande , mais si vous devez fermer la connexion, faites attention. Vous devez simplement le fermer si vous êtes sûr que toutes les mises à jour ont été exécutées.
Une erreur courante consiste à appeler db.close() après la distribution de toutes les mises à jour sans savoir si elles sont terminées. Si vous faites cela, vous obtiendrez des erreurs.
Mauvaise implémentation :
collection.find(query).each(function(err, doc) {
if (err) throw err;
if (doc) {
collection.update(query, update, function(err, updated) {
// handle
});
}
else {
db.close(); // if there is any pending update, it will throw an error there
}
});
Cependant, étant donné que db.close() est également une opération asynchrone ( sa signature possède une option de rappel), vous pouvez être chanceux et ce code peut se terminer sans erreur. Cela peut ne fonctionner que lorsque vous ne devez mettre à jour que quelques documents dans une petite collection (alors n'essayez pas).
Solution correcte:
Comme une solution asynchrone avait déjà été proposée par Leonid , voici une solution utilisant Q promesses.
var Q = require('q');
var client = require('mongodb').MongoClient;
var url = 'mongodb://localhost:27017/test';
client.connect(url, function(err, db) {
if (err) throw err;
var promises = [];
var query = {}; // select all docs
var collection = db.collection('demo');
var cursor = collection.find(query);
// read all docs
cursor.each(function(err, doc) {
if (err) throw err;
if (doc) {
// create a promise to update the doc
var query = doc;
var update = { $set: {hi: 'there'} };
var promise =
Q.npost(collection, 'update', [query, update])
.then(function(updated){
console.log('Updated: ' + updated);
});
promises.Push(promise);
} else {
// close the connection after executing all promises
Q.all(promises)
.then(function() {
if (cursor.isClosed()) {
console.log('all items have been processed');
db.close();
}
})
.fail(console.error);
}
});
});
Le node-mongodb-native prend désormais en charge un paramètre endCallback pour cursor.forEach Quant à celui qui gère l’événement APRÈS l’itération complète, reportez-vous au document officiel pour plus de détails http://mongodb.github.io/node-mongodb-native/2.2/api/Cursor.html#forEach .
Notez également que . Each est maintenant obsolète dans le pilote natif de nodejs.
Et voici un exemple d'utilisation d'un curseur Mongoose async avec des promesses:
new Promise(function (resolve, reject) {
collection.find(query).cursor()
.on('data', function(doc) {
// ...
})
.on('error', reject)
.on('end', resolve);
})
.then(function () {
// ...
});
Référence:
Aucune des réponses précédentes ne mentionne le traitement par lots des mises à jour. Cela les rend extrêmement lent ???? - Des dizaines ou des centaines de fois plus lent qu'une solution utilisant bulkWrite .
Supposons que vous souhaitiez doubler la valeur d'un champ dans chaque document. Voici comment faire ça rapidement ???? et avec consommation de mémoire fixe:
// Double the value of the 'foo' field in all documents
let bulkWrites = [];
const bulkDocumentsSize = 100; // how many documents to write at once
let i = 0;
db.collection.find({ ... }).forEach(doc => {
i++;
// Update the document...
doc.foo = doc.foo * 2;
// Add the update to an array of bulk operations to execute later
bulkWrites.Push({
replaceOne: {
filter: { _id: doc._id },
replacement: doc,
},
});
// Update the documents and log progress every `bulkDocumentsSize` documents
if (i % bulkDocumentsSize === 0) {
db.collection.bulkWrite(bulkWrites);
bulkWrites = [];
print(`Updated ${i} documents`);
}
});
// Flush the last <100 bulk writes
db.collection.bulkWrite(bulkWrites);