Comment structurer un modèle dans MVC?
Je commence tout juste à comprendre le framework MVC et je me demande souvent combien de code devrait être inséré dans le modèle. J'ai tendance à avoir une classe d'accès aux données qui a des méthodes comme celle-ci:
public function CheckUsername($connection, $username)
{
try
{
$data = array();
$data['Username'] = $username;
//// SQL
$sql = "SELECT Username FROM" . $this->usersTableName . " WHERE Username = :Username";
//// Execute statement
return $this->ExecuteObject($connection, $sql, $data);
}
catch(Exception $e)
{
throw $e;
}
}
Mes modèles ont tendance à être une classe d'entités mappée à la table de base de données.
L'objet de modèle doit-il avoir toutes les propriétés mappées de la base de données ainsi que le code ci-dessus ou est-il correct de séparer ce code qui fait fonctionner la base de données?
Vais-je finir par avoir quatre couches?
Avertissement: Ce qui suit est une description de ma compréhension des modèles de type MVC dans le contexte des applications Web basées sur PHP. Tous les liens externes qui sont utilisés dans le contenu sont là pour expliquer les termes et les concepts, et pas pour impliquer ma propre crédibilité sur le sujet.
La première chose que je dois éclaircir est la suivante: le modèle est une couche .
Deuxièmement: il y a une différence entre classical MVC et ce que nous utilisons dans le développement Web. Voici un peu d'une réponse plus ancienne que j'ai écrite, qui décrit brièvement en quoi elles sont différentes.
Quel modèle n'est PAS:
Le modèle n'est pas une classe ou un objet unique. C'est une erreur très courante de faire (je l'ai fait aussi, bien que la réponse originale ait été écrite quand j'ai commencé à apprendre le contraire) , car la plupart des frameworks perpétuent cette idée fausse.
Ce n'est pas non plus une technique ORM (Object-Relational Mapping), ni une abstraction de tables de base de données. Quiconque vous dira le contraire essaiera probablement de 'vendre' un autre ORM flambant neuf ou un cadre complet.
Qu'est-ce qu'un modèle?
Dans une adaptation MVC appropriée, le M contient toute la logique métier du domaine et la Model Layer est principalement à partir de trois types de structures:
Un objet de domaine est un conteneur logique d'informations purement de domaine; il représente généralement une entité logique dans l'espace du domaine problématique. Communément appelé logique d'entreprise .
C’est là que vous définissez comment valider les données avant d’envoyer une facture ou calculer le coût total d’une commande. Dans le même temps, Domain Objects ne sont absolument pas conscients du stockage - ni de où (base de données SQL, REST API , fichier texte, etc.) ni même if ils sont enregistrés ou récupérés.
Ces objets ne sont responsables que du stockage. Si vous stockez des informations dans une base de données, c'est là que réside le SQL. Ou peut-être utilisez-vous un fichier XML pour stocker des données, et vos Data Mappers analysent des fichiers XML.
Vous pouvez les considérer comme des "objets de domaine de niveau supérieur", mais au lieu de la logique métier, Services sont responsables de l'interaction entre Domain Objects et Mappers . Ces structures finissent par créer une interface "publique" pour interagir avec la logique métier du domaine. Vous pouvez les éviter, mais sous peine de perdre de la logique de domaine dans Controllers .
Il existe une réponse connexe à ce sujet dans la ACL implementation question - cela pourrait être utile.
La communication entre la couche de modèle et les autres parties du triade MVC ne doit se faire que par le biais de Services . La séparation claire présente quelques avantages supplémentaires:
- il est utile d'appliquer le principe de responsabilité unique (SRP)
- fournit une marge de manœuvre supplémentaire en cas de changement de logique
- maintient le contrôleur aussi simple que possible
- donne un plan clair, si jamais vous avez besoin d'une API externe
Comment interagir avec un modèle?
Prérequis: regarder des conférences "État global et singletons" et "Ne cherchez pas de choses!" Des discussions sur le code propre.
Accéder aux instances de service
Pour que les instances View et Controller (que vous puissiez appeler: "couche d'interface utilisateur") aient accès à ces services, il existe: deux approches générales:
- Vous pouvez injecter directement les services requis dans les constructeurs de vos vues et contrôleurs, de préférence à l'aide d'un conteneur DI.
- Utiliser une fabrique pour les services comme dépendance obligatoire pour tous vos vues et contrôleurs.
Comme vous pouvez le supposer, le conteneur DI est une solution beaucoup plus élégante (sans être la plus simple pour un débutant). Les deux bibliothèques que je recommande d'utiliser pour cette fonctionnalité sont le composant DependencyInjection autonome de Syfmony ou Auryn .
Les solutions utilisant une fabrique et un conteneur DI vous permettraient également de partager les instances de différents serveurs à partager entre le contrôleur sélectionné et la vue pour un cycle de requête-réponse donné.
Modification de l'état du modèle
Maintenant que vous pouvez accéder à la couche de modèle dans les contrôleurs, vous devez commencer à les utiliser:
public function postLogin(Request $request)
{
$email = $request->get('email');
$identity = $this->identification->findIdentityByEmailAddress($email);
$this->identification->loginWithPassword(
$identity,
$request->get('password')
);
}
Vos contrôleurs ont une tâche très claire: saisissez les entrées utilisateur et, sur la base de ces entrées, modifiez l'état actuel de la logique métier. Dans cet exemple, les états modifiés entre "utilisateur anonyme" et "utilisateur connecté".
Le contrôleur n'est pas responsable de la validation de la saisie de l'utilisateur, car cela fait partie des règles métier et le contrôleur n'appelle en aucun cas des requêtes SQL, comme ce que vous verriez ici ou ici (s'il vous plaît, ne les haïssez pas, ils sont égarés, pas méchants).
Montrer à l'utilisateur le changement d'état.
Ok, l'utilisateur s'est connecté (ou a échoué). Maintenant quoi? Cet utilisateur n'en est toujours pas conscient. Donc, vous devez réellement produire une réponse et c'est la responsabilité d'un point de vue.
public function postLogin()
{
$path = '/login';
if ($this->identification->isUserLoggedIn()) {
$path = '/dashboard';
}
return new RedirectResponse($path);
}
Dans ce cas, la vue produisait l'une des deux réponses possibles, en fonction de l'état actuel de la couche de modèle. Dans un cas d'utilisation différent, la vue choisirait différents modèles à restituer, sur la base de "type de l'article sélectionné".
La couche de présentation peut en réalité devenir assez complexe, comme décrit ici: Comprendre les vues MVC en PHP .
Mais je fais juste une API REST!
Bien sûr, il y a des situations où il y a trop de travail.
MVC n'est qu'une solution concrète pour la séparation des préoccupations principe. MVC sépare l'interface utilisateur de la logique métier et, dans l'interface utilisateur, il sépare le traitement de l'entrée utilisateur et de la présentation. C'est crucial. Bien que les gens le décrivent souvent comme une "triade", il n’est pas composé de trois parties indépendantes. La structure ressemble plus à ceci:

Cela signifie que, lorsque la logique de votre couche de présentation est presque inexistante, l'approche pragmatique consiste à les conserver en tant que couche unique. Cela peut également considérablement simplifier certains aspects de la couche de modèle.
En utilisant cette approche, l'exemple de connexion (pour une API) peut être écrit comme suit:
public function postLogin(Request $request)
{
$email = $request->get('email');
$data = [
'status' => 'ok',
];
try {
$identity = $this->identification->findIdentityByEmailAddress($email);
$token = $this->identification->loginWithPassword(
$identity,
$request->get('password')
);
} catch (FailedIdentification $exception) {
$data = [
'status' => 'error',
'message' => 'Login failed!',
]
}
return new JsonResponse($data);
}
Bien que cela ne soit pas viable, lorsque vous avez une logique compliquée pour restituer un corps de réponse, cette simplification est très utile pour des scénarios plus triviaux. Mais , soyez averti , cette approche deviendra un cauchemar si vous essayez de l'utiliser dans de grandes bases de code avec une logique de présentation complexe.
Comment construire le modèle?
Puisqu'il n'y a pas une seule classe "Modèle" (comme expliqué ci-dessus), vous ne "construisez pas le modèle". Au lieu de cela, vous commencez à créer Services , qui sont capables d’exécuter certaines méthodes. Et ensuite, implémentez Domain Objects et Mappers .
Un exemple de méthode de service:
Dans les deux approches ci-dessus, il existait cette méthode de connexion pour le service d'identification. À quoi cela ressemblerait-il réellement. J'utilise une version légèrement modifiée de la même fonctionnalité provenant de une bibliothèque , que j'ai écrite .. parce que je suis paresseux:
public function loginWithPassword(Identity $identity, string $password): string
{
if ($identity->matchPassword($password) === false) {
$this->logWrongPasswordNotice($identity, [
'email' => $identity->getEmailAddress(),
'key' => $password, // this is the wrong password
]);
throw new PasswordMismatch;
}
$identity->setPassword($password);
$this->updateIdentityOnUse($identity);
$cookie = $this->createCookieIdentity($identity);
$this->logger->info('login successful', [
'input' => [
'email' => $identity->getEmailAddress(),
],
'user' => [
'account' => $identity->getAccountId(),
'identity' => $identity->getId(),
],
]);
return $cookie->getToken();
}
Comme vous pouvez le constater, à ce niveau d'abstraction, rien n'indique d'où les données ont été extraites. Il peut s'agir d'une base de données, mais également d'un objet fictif à des fins de test. Même les mappeurs de données, qui sont réellement utilisés pour cela, sont cachés dans les méthodes private de ce service.
private function changeIdentityStatus(Entity\Identity $identity, int $status)
{
$identity->setStatus($status);
$identity->setLastUsed(time());
$mapper = $this->mapperFactory->create(Mapper\Identity::class);
$mapper->store($identity);
}
Façons de créer des mappeurs
Pour implémenter une abstraction de la persistance, sur les approches les plus souples, vous devez créer des mappeurs de données personnalisés .
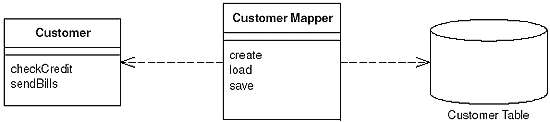
De: PoEAA book
En pratique, ils sont mis en œuvre pour une interaction avec des classes ou des superclasses spécifiques. Disons que vous avez Customer et Admin dans votre code (les deux héritant d'une superclasse User). Tous deux finiraient probablement par avoir un mappeur de correspondance séparé, car ils contiennent des champs différents. Mais vous vous retrouverez également avec des opérations partagées et couramment utilisées. Par exemple: mettre à jour le "dernier vu en ligne" heure. Et au lieu de rendre les mappeurs existants plus compliqués, l’approche la plus pragmatique consiste à avoir un "mappeur utilisateur" général, qui ne fait que mettre à jour cet horodatage.
Quelques commentaires supplémentaires:
Tables de base de données et modèle
Bien que, parfois, il existe une relation directe 1: 1: 1 entre une table de base de données, Domain Object , et Mapper , dans les grands projets il pourrait être moins commun que prévu
Les informations utilisées par un seul Domain Object peuvent être mappées à partir de différentes tables, tandis que l'objet lui-même n'a pas de persistance dans la base de données.
Exemple: si vous générez un rapport mensuel. Cela permettrait de collecter des informations provenant de différentes tables, mais il n’existe pas de table magique
MonthlyReportdans la base de données.Un seul Mapper peut affecter plusieurs tables.
Exemple: lorsque vous stockez des données à partir de l'objet
User, ceci Domain Object peut contenir une collection d'autres objets de domaine. -Groupinstances. Si vous les modifiez et stockez laUser, le Data Mapper devra mettre à jour et/ou insérer des entrées dans plusieurs tables.Les données provenant d'un seul Domain Object sont stockées dans plusieurs tables.
Exemple: Dans les grands systèmes (par exemple, un réseau social de taille moyenne), il peut être pragmatique de stocker les données d'authentification des utilisateurs et les données fréquemment consultées séparément des gros morceaux de contenu, qui est rarement requis. Dans ce cas, vous pouvez toujours avoir une seule classe
User, mais les informations qu'elle contient dépendent du fait que des informations complètes ont été extraites ou non.Pour chaque Domain Object il peut y avoir plus d'un mappeur
Exemple: vous avez un site de nouvelles avec une base de code partagée pour le logiciel destiné au public et au logiciel de gestion. Mais, bien que les deux interfaces utilisent la même classe
Article, la gestion a besoin de beaucoup d’informations supplémentaires. Dans ce cas, vous auriez deux mappeurs distincts: "interne" et "externe". Chacun effectuant des requêtes différentes, ou même utilise différentes bases de données (comme maître ou esclave).
Une vue n'est pas un modèle
View Les instances dans MVC (si vous n'utilisez pas la variante MVP du modèle) sont responsables de la logique de présentation. Cela signifie que chaque View jonglera généralement avec au moins quelques modèles. Il acquiert les données de Model Layer puis, en fonction des informations reçues, choisit un modèle et définit des valeurs.
L'un des avantages que vous en retirez est la possibilité de réutilisation. Si vous créez une classe
ListView, alors, avec un code bien écrit, vous pouvez demander à la même classe de gérer la présentation de la liste d'utilisateurs et les commentaires sous un article. Parce qu'ils ont tous les deux la même logique de présentation. Vous venez de changer de modèle.Vous pouvez utiliser des modèles PHP natifs ou un moteur de modélisation tiers. Certaines bibliothèques tierces peuvent également remplacer intégralement les instances View .
Qu'en est-il de l'ancienne version de la réponse?
Le seul changement majeur est que, ce qui s'appelle Model dans l'ancienne version, est en fait un Service . Le reste de "l'analogie de la bibliothèque" continue à bien marcher.
Le seul défaut que je vois est que ce serait une bibliothèque vraiment étrange, car elle vous renverrait des informations du livre, mais ne vous laisserait pas toucher le livre lui-même, car sinon l'abstraction commencerait à "fuir". Je devrais peut-être penser à une analogie plus appropriée.
Quelle est la relation entre View et Controller instances?
La structure MVC est composée de deux couches: ui et model. Les principales structures de la UI layer sont les vues et le contrôleur.
Lorsque vous traitez avec des sites Web utilisant un modèle de conception MVC, le meilleur moyen consiste à établir une relation 1: 1 entre les vues et les contrôleurs. Chaque vue représente une page entière de votre site Web et dispose d'un contrôleur dédié pour gérer toutes les demandes entrantes pour cette vue particulière.
Par exemple, pour représenter un article ouvert, vous devez utiliser
\Application\Controller\Documentet\Application\View\Document. Cela contiendrait toutes les fonctionnalités principales de la couche d'interface utilisateur, quand il s'agirait de traiter des articles (bien sûr, vous pourriez avoir quelques XHR composants/qui ne sont pas directement liés aux articles) .
Tout ce qui est logique applicative appartient à un modèle, qu'il s'agisse d'une interrogation de base de données, de calculs, d'un appel REST, etc.
Vous pouvez avoir l'accès aux données dans le modèle lui-même, le modèle MVC ne vous empêche pas de le faire. Vous pouvez y ajouter des services, des mappeurs et autres, mais la définition même d'un modèle est une couche qui gère la logique métier, rien de plus, rien de moins. Ce peut être une classe, une fonction ou un module complet avec un million d’objets si vous le souhaitez.
Il est toujours plus facile d'avoir un objet séparé qui exécute les requêtes de base de données au lieu de les exécuter directement dans le modèle: cela sera particulièrement utile lors des tests unitaires (en raison de la facilité d'injection d'une dépendance de base de données fictive dans votre modèle):
class Database {
protected $_conn;
public function __construct($connection) {
$this->_conn = $connection;
}
public function ExecuteObject($sql, $data) {
// stuff
}
}
abstract class Model {
protected $_db;
public function __construct(Database $db) {
$this->_db = $db;
}
}
class User extends Model {
public function CheckUsername($username) {
// ...
$sql = "SELECT Username FROM" . $this->usersTableName . " WHERE ...";
return $this->_db->ExecuteObject($sql, $data);
}
}
$db = new Database($conn);
$model = new User($db);
$model->CheckUsername('foo');
En outre, en PHP, vous devez rarement capturer/rediffuser des exceptions car la trace est conservée, en particulier dans un cas similaire à votre exemple. Laissez simplement l'exception être levée et attrapez-la dans le contrôleur à la place.
Dans Web- "MVC", vous pouvez faire ce que vous voulez.
Le concept original (1) a décrit le modèle comme étant la logique métier. Il doit représenter l'état de l'application et imposer une certaine cohérence aux données. Cette approche est souvent décrite comme un "modèle modèle".
La plupart des frameworks PHP suivent une approche plus superficielle, où le modèle est simplement une interface de base de données. Mais à tout le moins, ces modèles doivent toujours valider les données et les relations entrantes.
De toute façon, vous n'êtes pas très loin si vous séparez les commandes SQL ou les appels de base de données dans une autre couche. De cette façon, vous ne devez vous préoccuper que des données/comportements réels, pas de l'API de stockage réelle. (Il est toutefois déraisonnable d'en faire trop. Par exemple, vous ne pourrez jamais remplacer une base de données par un fichier stocké si celui-ci n'était pas conçu à l'avance.)
Le plus souvent, la plupart des applications auront des données, des affichages et un traitement et nous allons simplement mettre celles-ci dans les lettres M, V et C.
Modèle (M) -> Possède les attributs qui contiennent l’état de l’application et ne connaissent rien de V et C.
View (V) -> Dispose du format d'affichage pour l'application et ne connaît que le mode de digestion du modèle, sans se soucier de C.
Contrôleur (C) ----> Traite une partie de l'application et sert de câblage entre M et V et cela dépend de M, V contrairement à M et V.
Au total, il existe une séparation des préoccupations entre chacun. À l'avenir, toute modification ou amélioration peut être ajoutée très facilement.
Dans mon cas, j'ai une classe de base de données qui gère toutes les interactions directes avec la base de données, telles que l'interrogation, la récupération, etc. Donc si je devais changer ma base de données de MySQL à PostgreSQL , il n'y aurait pas de problème. Il peut donc être utile d’ajouter cette couche supplémentaire.
Chaque table peut avoir sa propre classe et ses propres méthodes, mais pour obtenir les données, la classe de base de données les gère:
Fichier Database.php
class Database {
private static $connection;
private static $current_query;
...
public static function query($sql) {
if (!self::$connection){
self::open_connection();
}
self::$current_query = $sql;
$result = mysql_query($sql,self::$connection);
if (!$result){
self::close_connection();
// throw custom error
// The query failed for some reason. here is query :: self::$current_query
$error = new Error(2,"There is an Error in the query.\n<b>Query:</b>\n{$sql}\n");
$error->handleError();
}
return $result;
}
....
public static function find_by_sql($sql){
if (!is_string($sql))
return false;
$result_set = self::query($sql);
$obj_arr = array();
while ($row = self::fetch_array($result_set))
{
$obj_arr[] = self::instantiate($row);
}
return $obj_arr;
}
}
Objet de table classL
class DomainPeer extends Database {
public static function getDomainInfoList() {
$sql = 'SELECT ';
$sql .='d.`id`,';
$sql .='d.`name`,';
$sql .='d.`shortName`,';
$sql .='d.`created_at`,';
$sql .='d.`updated_at`,';
$sql .='count(q.id) as queries ';
$sql .='FROM `domains` d ';
$sql .='LEFT JOIN queries q on q.domainId = d.id ';
$sql .='GROUP BY d.id';
return self::find_by_sql($sql);
}
....
}
J'espère que cet exemple vous aidera à créer une bonne structure.