Quelle est la meilleure façon de PHP lire les dernières lignes d'un fichier?
Dans mon application PHP, je dois lire plusieurs lignes à partir de la fin de Nombreux fichiers (principalement des journaux). Parfois, je n'ai besoin que du dernier, parfois, de dizaines, voire de centaines. En gros, je veux quelque chose d'aussi souple que la commande Unix tail
Il y a des questions ici sur la façon d'obtenir la dernière ligne d'un fichier (mais J'ai besoin de N lignes), et différentes solutions ont été données. Je ne suis pas sûr de savoir lequel Est le meilleur et qui fonctionne mieux.
Vue d'ensemble des méthodes
En cherchant sur Internet, je suis tombé sur différentes solutions. Je peux les regrouper en trois approches:
- naïfs utilisant
file()PHP function; - triche ceux qui exécutent la commande
tailsur le système; - puissants qui sautent volontiers autour d'un fichier ouvert en utilisant
fseek().
J'ai fini par choisir (ou écrire) cinq solutions, une naïve , une tricherie une et trois puissants .
- La solution la plus concise naïve , à l'aide de fonctions de tableau intégrées.
- La seule solution possible basée sur la commande
tail, ce qui pose un gros problème: elle ne s'exécute pas sitailn'est pas disponible, comme sur les environnements non Unix (Windows) ou restreints qui n'autorisent pas les fonctions système. - La solution dans laquelle des octets simples sont lus depuis la fin du fichier en recherchant (et en comptant) les caractères de nouvelle ligne, trouvés ici.
- La solution sur plusieurs octets en mémoire tampon optimisée pour les gros fichiers, trouvée ici.
- Une version légèrement modifiée de la solution n ° 4 dans laquelle la longueur du tampon est dynamique, décidée en fonction du nombre de lignes à récupérer.
Toutes les solutions fonctionnent . En ce sens qu'ils renvoient le résultat attendu de n'importe quel fichier et pour n'importe quel nombre de lignes que nous demandons (sauf pour la solution n ° 1, cela peut casser PHP limites de mémoire en cas de fichiers volumineux, sans rien retourner). Mais lequel est le meilleur?
Des tests de performance
Pour répondre à la question, je lance des tests. C'est comme ça que ces choses sont faites, n'est-ce pas?
J'ai préparé un exemple de fichier de 100 Ko réunissant différents fichiers trouvés dans mon répertoire /var/log. Ensuite, j'ai écrit un script PHP qui utilise chacune des cinq solutions pour récupérer 1, 2, .., 10, 20, ... 100, 200, ... , 1000 lignes à partir de la fin du fichier. Chaque test est répété dix fois (c'est-à-dire quelque chose comme 5 × 28 × 10 = 1400 tests), en mesurant la durée moyenne écoulée en microsecondes.
J'exécute le script sur ma machine de développement locale (Xubuntu 12.04, PHP 5.3.10, processeur à double cœur de 2,70 GHz, 2 Go de RAM) en utilisant l'interpréteur de ligne de commande PHP. Voici les résultats:
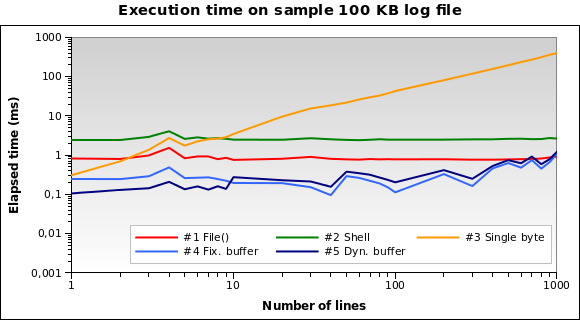
Les solutions n ° 1 et n ° 2 semblent être les pires. La solution n ° 3 n’est valable que lorsque nous avons besoin de lire quelques lignes. Les solutions n ° 4 et n ° 5 semblent être les meilleures. Notez à quel point la taille de la mémoire tampon dynamique permet d'optimiser l'algorithme: le temps d'exécution est un peu plus court pour quelques lignes. , à cause du tampon réduit.
Essayons avec un fichier plus gros. Que faire si nous devons lire un fichier journal 10 Mo ?
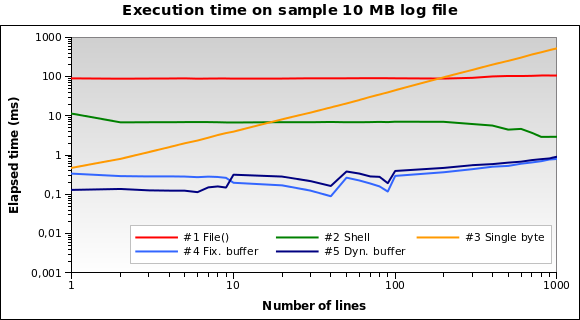
Maintenant, la solution n ° 1 est de loin la pire: en fait, charger tout le fichier de 10 Mo en mémoire n’est pas une bonne idée. Je lance également les tests sur des fichiers de 1Mo et 100Mo, et la situation est pratiquement la même.
Et pour les fichiers journaux minuscules? C'est le graphique pour un fichier 10 KB :
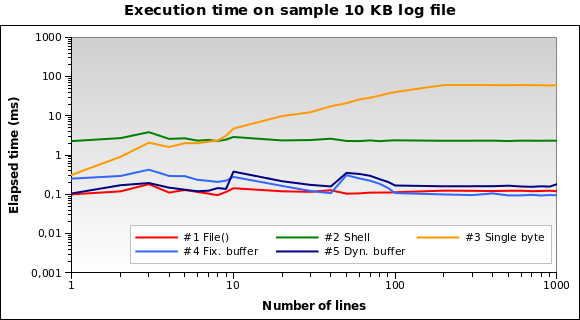
La solution n ° 1 est la meilleure maintenant! Le chargement de 10 Ko en mémoire n'est pas un gros problème pour PHP. De plus, les n ° 4 et 5 fonctionnent bien. Cependant, il s’agit d’un cas Edge: un journal de 10 Ko signifie quelque chose comme 150/200 lignes ...
Vous pouvez télécharger tous mes fichiers de test, sources et résultats ici .
Dernières pensées
Solution n ° 5 est fortement recommandé pour les cas d'utilisation courants: fonctionne très bien avec chaque taille de fichier et fonctionne particulièrement bien lors de la lecture d'un fichier. quelques lignes.
Évitez solution n ° 1 si vous devez lire des fichiers de plus de 10 Ko.
Solution # 2 et # ne sont pas les meilleurs pour chaque test que je lance: le n ° 2 ne s'exécute jamais en moins de 2 ms, et le n ° 3 est fortement influencé par le nombre de lignes que vous demandez (fonctionne plutôt bien uniquement avec 1 ou 2 lignes ).
Ceci est une version modifiée qui peut également ignorer les dernières lignes:
/**
* Modified version of http://www.geekality.net/2011/05/28/php-tail-tackling-large-files/ and of https://Gist.github.com/lorenzos/1711e81a9162320fde20
* @author Kinga the Witch (Trans-dating.com), Torleif Berger, Lorenzo Stanco
* @link http://stackoverflow.com/a/15025877/995958
* @license http://creativecommons.org/licenses/by/3.0/
*/
function tailWithSkip($filepath, $lines = 1, $skip = 0, $adaptive = true)
{
// Open file
$f = @fopen($filepath, "rb");
if (@flock($f, LOCK_SH) === false) return false;
if ($f === false) return false;
if (!$adaptive) $buffer = 4096;
else {
// Sets buffer size, according to the number of lines to retrieve.
// This gives a performance boost when reading a few lines from the file.
$max=max($lines, $skip);
$buffer = ($max < 2 ? 64 : ($max < 10 ? 512 : 4096));
}
// Jump to last character
fseek($f, -1, SEEK_END);
// Read it and adjust line number if necessary
// (Otherwise the result would be wrong if file doesn't end with a blank line)
if (fread($f, 1) == "\n") {
if ($skip > 0) { $skip++; $lines--; }
} else {
$lines--;
}
// Start reading
$output = '';
$chunk = '';
// While we would like more
while (ftell($f) > 0 && $lines >= 0) {
// Figure out how far back we should jump
$seek = min(ftell($f), $buffer);
// Do the jump (backwards, relative to where we are)
fseek($f, -$seek, SEEK_CUR);
// Read a chunk
$chunk = fread($f, $seek);
// Calculate chunk parameters
$count = substr_count($chunk, "\n");
$strlen = mb_strlen($chunk, '8bit');
// Move the file pointer
fseek($f, -$strlen, SEEK_CUR);
if ($skip > 0) { // There are some lines to skip
if ($skip > $count) { $skip -= $count; $chunk=''; } // Chunk contains less new line symbols than
else {
$pos = 0;
while ($skip > 0) {
if ($pos > 0) $offset = $pos - $strlen - 1; // Calculate the offset - NEGATIVE position of last new line symbol
else $offset=0; // First search (without offset)
$pos = strrpos($chunk, "\n", $offset); // Search for last (including offset) new line symbol
if ($pos !== false) $skip--; // Found new line symbol - skip the line
else break; // "else break;" - Protection against infinite loop (just in case)
}
$chunk=substr($chunk, 0, $pos); // Truncated chunk
$count=substr_count($chunk, "\n"); // Count new line symbols in truncated chunk
}
}
if (strlen($chunk) > 0) {
// Add chunk to the output
$output = $chunk . $output;
// Decrease our line counter
$lines -= $count;
}
}
// While we have too many lines
// (Because of buffer size we might have read too many)
while ($lines++ < 0) {
// Find first newline and remove all text before that
$output = substr($output, strpos($output, "\n") + 1);
}
// Close file and return
@flock($f, LOCK_UN);
fclose($f);
return trim($output);
}
Cela fonctionnerait aussi:
$file = new SplFileObject("/path/to/file");
$file->seek(PHP_INT_MAX); // cheap trick to seek to EoF
$total_lines = $file->key(); // last line number
// output the last twenty lines
$reader = new LimitIterator($file, $total_lines - 20);
foreach ($reader as $line) {
echo $line; // includes newlines
}
Ou sans la LimitIterator:
$file = new SplFileObject($filepath);
$file->seek(PHP_INT_MAX);
$total_lines = $file->key();
$file->seek($total_lines - 20);
while (!$file->eof()) {
echo $file->current();
$file->next();
}
Malheureusement, votre test segfaults sur ma machine, je ne peux donc pas dire comment il fonctionne.
Ma petite solution de copier/coller après avoir lu tout cela ici. tail () ne ferme pas $ fp car vous devez quand même le tuer avec Ctrl-C. usleep pour gagner du temps sur votre cpu, uniquement testé sur windows à ce jour. Vous devez mettre ce code dans une classe!
/**
* @param $pathname
*/
private function tail($pathname)
{
$realpath = realpath($pathname);
$fp = fopen($realpath, 'r', FALSE);
$lastline = '';
fseek($fp, $this->tailonce($pathname, 1, false), SEEK_END);
do {
$line = fread($fp, 1000);
if ($line == $lastline) {
usleep(50);
} else {
$lastline = $line;
echo $lastline;
}
} while ($fp);
}
/**
* @param $pathname
* @param $lines
* @param bool $echo
* @return int
*/
private function tailonce($pathname, $lines, $echo = true)
{
$realpath = realpath($pathname);
$fp = fopen($realpath, 'r', FALSE);
$flines = 0;
$a = -1;
while ($flines <= $lines) {
fseek($fp, $a--, SEEK_END);
$char = fread($fp, 1);
if ($char == "\n") $flines++;
}
$out = fread($fp, 1000000);
fclose($fp);
if ($echo) echo $out;
return $a+2;
}
J'aime la méthode suivante, mais cela ne fonctionnera pas avec des fichiers allant jusqu'à 2 Go.
<?php
function lastLines($file, $lines) {
$size = filesize($file);
$fd=fopen($file, 'r+');
$pos = $size;
$n=0;
while ( $n < $lines+1 && $pos > 0) {
fseek($fd, $pos);
$a = fread($fd, 1);
if ($a === "\n") {
++$n;
};
$pos--;
}
$ret = array();
for ($i=0; $i<$lines; $i++) {
array_Push($ret, fgets($fd));
}
return $ret;
}
print_r(lastLines('hola.php', 4));
?>
Encore une autre fonction, vous pouvez utiliser des expressions rationnelles pour séparer les éléments. Usage
$last_rows_array = file_get_tail('logfile.log', 100, array(
'regex' => true, // use regex
'separator' => '#\n{2,}#', // separator: at least two newlines
'typical_item_size' => 200, // line length
));
La fonction:
// public domain
function file_get_tail( $file, $requested_num = 100, $args = array() ){
// default arg values
$regex = true;
$separator = null;
$typical_item_size = 100; // estimated size
$more_size_mul = 1.01; // +1%
$max_more_size = 4000;
extract( $args );
if( $separator === null ) $separator = $regex ? '#\n+#' : "\n";
if( is_string( $file )) $f = fopen( $file, 'rb');
else if( is_resource( $file ) && in_array( get_resource_type( $file ), array('file', 'stream'), true ))
$f = $file;
else throw new \Exception( __METHOD__.': file must be either filename or a file or stream resource');
// get file size
fseek( $f, 0, SEEK_END );
$fsize = ftell( $f );
$fpos = $fsize;
$bytes_read = 0;
$all_items = array(); // array of array
$all_item_num = 0;
$remaining_num = $requested_num;
$last_junk = '';
while( true ){
// calc size and position of next chunk to read
$size = $remaining_num * $typical_item_size - strlen( $last_junk );
// reading a bit more can't hurt
$size += (int)min( $size * $more_size_mul, $max_more_size );
if( $size < 1 ) $size = 1;
// set and fix read position
$fpos = $fpos - $size;
if( $fpos < 0 ){
$size -= -$fpos;
$fpos = 0;
}
// read chunk + add junk from prev iteration
fseek( $f, $fpos, SEEK_SET );
$chunk = fread( $f, $size );
if( strlen( $chunk ) !== $size ) throw new \Exception( __METHOD__.": read error?");
$bytes_read += strlen( $chunk );
$chunk .= $last_junk;
// chunk -> items, with at least one element
$items = $regex ? preg_split( $separator, $chunk ) : explode( $separator, $chunk );
// first item is probably cut in half, use it in next iteration ("junk") instead
// also skip very first '' item
if( $fpos > 0 || $items[0] === ''){
$last_junk = $items[0];
unset( $items[0] );
} // … else noop, because this is the last iteration
// ignore last empty item. end( empty [] ) === false
if( end( $items ) === '') array_pop( $items );
// if we got items, Push them
$num = count( $items );
if( $num > 0 ){
$remaining_num -= $num;
// if we read too much, use only needed items
if( $remaining_num < 0 ) $items = array_slice( $items, - $remaining_num );
// don't fix $remaining_num, we will exit anyway
$all_items[] = array_reverse( $items );
$all_item_num += $num;
}
// are we ready?
if( $fpos === 0 || $remaining_num <= 0 ) break;
// calculate a better estimate
if( $all_item_num > 0 ) $typical_item_size = (int)max( 1, round( $bytes_read / $all_item_num ));
}
fclose( $f );
//tr( $all_items );
return call_user_func_array('array_merge', $all_items );
}