Accéder aux clés dict comme un attribut?
Je trouve plus pratique d’accéder aux clés dict en tant que obj.foo au lieu de obj['foo'], j’ai donc écrit cet extrait:
class AttributeDict(dict):
def __getattr__(self, attr):
return self[attr]
def __setattr__(self, attr, value):
self[attr] = value
Cependant, je suppose qu'il doit y avoir une raison pour que Python ne fournisse pas cette fonctionnalité immédiatement. Quelles seraient les mises en garde et les pièges pour accéder aux clés de dict de cette manière?
La meilleure façon de faire est:
class AttrDict(dict):
def __init__(self, *args, **kwargs):
super(AttrDict, self).__init__(*args, **kwargs)
self.__dict__ = self
Quelques pros:
- Cela fonctionne réellement!
- Aucune méthode de classe de dictionnaire n'est ombrée (par exemple,
.keys()fonctionne parfaitement) - Les attributs et les éléments sont toujours synchronisés
- Essayer d'accéder à une clé inexistante alors qu'un attribut soulève correctement
AttributeErrorau lieu deKeyError
Les inconvénients:
- Des méthodes comme
.keys()fonctionneront pas si elles sont écrasées par les données entrantes - Provoque un fuite de mémoire dans Python <2.7.4/Python3 <3.2.3
- Pylint va banane avec
E1123(unexpected-keyword-arg)etE1103(maybe-no-member) - Pour les non-initiés, cela ressemble à de la magie pure.
Une courte explication sur la façon dont cela fonctionne
- Tous les objets python stockent en interne leurs attributs dans un dictionnaire nommé
__dict__. - Il n'est pas nécessaire que le dictionnaire interne
__dict__doive être "un simple dicton". Nous pouvons donc affecter n'importe quelle sous-classe dedict()au dictionnaire interne. - Dans notre cas, nous assignons simplement l'instance
AttrDict()que nous instancions (comme dans__init__). - En appelant la méthode
super()de__init__(), nous nous sommes assurés qu'il se comporte (déjà) exactement comme un dictionnaire, car cette fonction appelle tout le code instanciation du dictionnaire.
Une des raisons pour lesquelles Python ne fournit pas cette fonctionnalité immédiatement
Comme indiqué dans la liste "inconvénients", ceci combine l'espace de noms des clés stockées (pouvant provenir de données arbitraires et/ou non fiables!) Avec l'espace de noms des attributs de la méthode dict intégrée. Par exemple:
d = AttrDict()
d.update({'items':["jacket", "necktie", "trousers"]})
for k, v in d.items(): # TypeError: 'list' object is not callable
print "Never reached!"
Vous pouvez avoir tous les caractères de chaîne légaux dans la clé si vous utilisez la notation de tableau ..__ Par exemple, obj['!#$%^&*()_']
From Cette autre question SO est un excellent exemple d'implémentation qui simplifie votre code existant. Que diriez-vous:
class AttributeDict(dict):
__getattr__ = dict.__getitem__
__setattr__ = dict.__setitem__
Beaucoup plus concis et ne laisse aucune place supplémentaire à vos fonctions __getattr__ et __setattr__ à l'avenir.
Où je réponds à la question qui a été posée
Pourquoi Python ne l’offre-t-il pas directement?
Je suppose que cela a à voir avec le Zen of Python : "Il devrait y en avoir un - et de préférence un seul - moyen évident de le faire." Cela créerait deux manières évidentes d'accéder aux valeurs des dictionnaires: obj['key'] et obj.key.
Mises en garde et pièges
Celles-ci incluent le possible manque de clarté et la confusion dans le code. c’est-à-dire que ce qui suit pourrait prêter à confusion pour une personne {else} qui conservera votre code ultérieurement, ou même pour vous, si vous n’y retournez pas pendant un moment. Encore une fois, de Zen : "La lisibilité compte!"
>>> KEY = 'spam'
>>> d[KEY] = 1
>>> # Several lines of miscellaneous code here...
... assert d.spam == 1
Si d est instancié ouKEY est défini oud[KEY] est attribué loin de l'endroit où d.spam est utilisé, cela peut facilement entraîner une confusion quant à ce qui est fait, car idiome couramment utilisé. Je sais que cela pourrait me confondre.
De plus, si vous modifiez la valeur de KEY comme suit (mais ne modifiez pas d.spam), vous obtenez maintenant:
>>> KEY = 'foo'
>>> d[KEY] = 1
>>> # Several lines of miscellaneous code here...
... assert d.spam == 1
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
AttributeError: 'C' object has no attribute 'spam'
OMI, ne vaut pas la peine.
Autres éléments
Comme d’autres l’ont déjà noté, vous pouvez utiliser n’importe quel objet hashable (pas seulement une chaîne) comme clé dict. Par exemple,
>>> d = {(2, 3): True,}
>>> assert d[(2, 3)] is True
>>>
est légal, mais
>>> C = type('C', (object,), {(2, 3): True})
>>> d = C()
>>> assert d.(2, 3) is True
File "<stdin>", line 1
d.(2, 3)
^
SyntaxError: invalid syntax
>>> getattr(d, (2, 3))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: getattr(): attribute name must be string
>>>
n'est pas. Cela vous donne accès à toute la gamme de caractères imprimables ou autres objets pouvant être utilisés pour vos clés de dictionnaire, que vous n'avez pas lors de l'accès à un attribut d'objet. Cela rend possible la magie d'une métaclasse d'objets en cache, comme la recette du Python Cookbook (Ch. 9) .
Où je éditorialise
Je préfère l'esthétique de spam.eggs à spam['eggs'] (je pense que ça a l'air plus propre), et j'ai vraiment commencé à avoir envie de cette fonctionnalité quand j'ai rencontré le namedtuple . Mais la commodité de pouvoir effectuer les opérations suivantes l’emporte.
>>> KEYS = 'spam eggs ham'
>>> VALS = [1, 2, 3]
>>> d = {k: v for k, v in Zip(KEYS.split(' '), VALS)}
>>> assert d == {'spam': 1, 'eggs': 2, 'ham': 3}
>>>
C’est un exemple simple, mais j’utilise fréquemment des dict dans des situations différentes de celles que j’utilisais avec la notation obj.key (c’est-à-dire lorsque je dois lire les préférences depuis un fichier XML). Dans d'autres cas, où je suis tenté d'instancier une classe dynamique et de lui appliquer des attributs pour des raisons esthétiques, je continue à utiliser un dict pour des raisons de cohérence afin d'améliorer la lisibilité.
Je suis sûr que l'OP a résolu ce problème depuis longtemps, mais s'il souhaite toujours cette fonctionnalité, je lui suggère de télécharger l'un des packages fournis par pypi qui la fournit:
Bunch est celui que je connais le mieux. Sous-classe dedict, vous avez donc toutes ces fonctionnalités.- AttrDict semble également très bon, mais je ne le connais pas aussi bien et je n'ai pas parcouru le code source avec autant de détails que j'ai Bunch .
- Comme indiqué dans les commentaires de Rotareti, Bunch est obsolète, mais il existe un fork actif appelé Munch.
Cependant, pour améliorer la lisibilité de son code, je lui recommande fortement de pas mélanger ses styles de notation. S'il préfère cette notation, il devrait simplement instancier un objet dynamique, y ajouter les attributs souhaités et l'appeler un jour:
>>> C = type('C', (object,), {})
>>> d = C()
>>> d.spam = 1
>>> d.eggs = 2
>>> d.ham = 3
>>> assert d.__dict__ == {'spam': 1, 'eggs': 2, 'ham': 3}
Où je mets à jour, pour répondre à une question de suivi dans les commentaires
Dans les commentaires (ci-dessous), Elmo demande:
Et si vous voulez aller plus loin? (en référence au type (...))
Bien que je n’aie jamais utilisé ce cas d’utilisation (là encore, j’ai tendance à utiliser la variable dict imbriquée, pour la cohérence .__), le code suivant fonctionne:
>>> C = type('C', (object,), {})
>>> d = C()
>>> for x in 'spam eggs ham'.split():
... setattr(d, x, C())
... i = 1
... for y in 'one two three'.split():
... setattr(getattr(d, x), y, i)
... i += 1
...
>>> assert d.spam.__dict__ == {'one': 1, 'two': 2, 'three': 3}
Caveat emptor: pour certaines raisons, des classes comme celle-ci semblent rompre le package de multitraitement. J'ai juste eu du mal avec ce bogue pendant un moment avant de trouver cet objet SO: Trouver une exception dans le multitraitement python
Et si vous vouliez une clé qui était une méthode, telle que __eq__ ou __getattr__?
Et vous ne pourriez pas avoir une entrée qui ne commence pas par une lettre, utilisez donc 0343853 comme clé.
Et si vous ne vouliez pas utiliser de ficelle?
Vous pouvez extraire une classe de conteneur pratique de la bibliothèque standard:
from argparse import Namespace
pour éviter de copier autour des bits de code. Pas d'accès standard au dictionnaire, mais facile à récupérer si vous le voulez vraiment. Le code dans argparse est simple,
class Namespace(_AttributeHolder):
"""Simple object for storing attributes.
Implements equality by attribute names and values, and provides a simple
string representation.
"""
def __init__(self, **kwargs):
for name in kwargs:
setattr(self, name, kwargs[name])
__hash__ = None
def __eq__(self, other):
return vars(self) == vars(other)
def __ne__(self, other):
return not (self == other)
def __contains__(self, key):
return key in self.__dict__
les tuples peuvent être utilisés comme clés de dictée. Comment voudriez-vous accéder à Tuple dans votre construction?
De plus, namedtuple est une structure pratique qui peut fournir des valeurs via l'accès aux attributs.
Cela ne fonctionne pas en général. Toutes les clés dict valides ne créent pas des attributs adressables ("la clé"). Donc, vous devrez faire attention.
Les objets Python sont essentiellement des dictionnaires. Donc, je doute qu'il y ait beaucoup de performance ou autre pénalité.
Voici un court exemple d'enregistrements immuables utilisant collections.namedtuple :
def record(name, d):
return namedtuple(name, d.keys())(**d)
et un exemple d'utilisation:
rec = record('Model', {
'train_op': train_op,
'loss': loss,
})
print rec.loss(..)
Cela ne répond pas à la question initiale, mais devrait être utile aux personnes qui, comme moi, se retrouvent ici à la recherche d'une bibliothèque fournissant cette fonctionnalité.
Addict c'est une excellente librairie pour ceci: https://github.com/mewwts/addict il prend en charge de nombreuses préoccupations mentionnées dans les réponses précédentes.
Un exemple tiré de la documentation:
body = {
'query': {
'filtered': {
'query': {
'match': {'description': 'addictive'}
},
'filter': {
'term': {'created_by': 'Mats'}
}
}
}
}
Avec toxicomane:
from addict import Dict
body = Dict()
body.query.filtered.query.match.description = 'addictive'
body.query.filtered.filter.term.created_by = 'Mats'
Que diriez-vous de Prodict , la petite classe Python que j'ai écrite pour les gouverner tous :)
De plus, vous obtenez auto-complétion de code, instanciations d'objet récursives et conversion de type auto!
Vous pouvez faire exactement ce que vous avez demandé:
p = Prodict()
p.foo = 1
p.bar = "baz"
Exemple 1: indication de type
class Country(Prodict):
name: str
population: int
turkey = Country()
turkey.name = 'Turkey'
turkey.population = 79814871
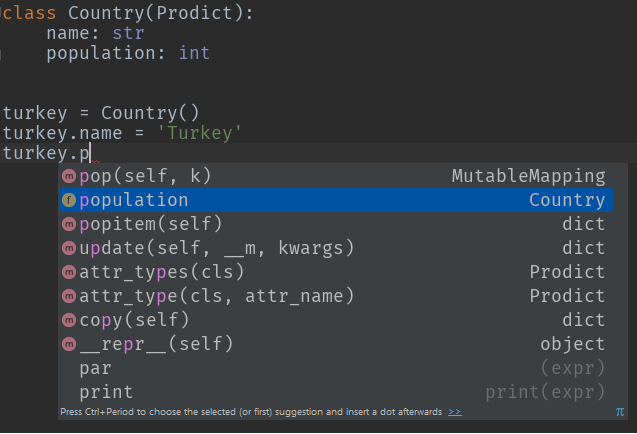
Exemple 2: conversion de type automatique
germany = Country(name='Germany', population='82175700', flag_colors=['black', 'red', 'yellow'])
print(germany.population) # 82175700
print(type(germany.population)) # <class 'int'>
print(germany.flag_colors) # ['black', 'red', 'yellow']
print(type(germany.flag_colors)) # <class 'list'>
Apparemment, il existe maintenant une bibliothèque pour cela - https://pypi.python.org/pypi/attrdict - qui implémente cette fonctionnalité exacte plus la fusion récursive et le chargement json. Ça vaut peut-être le coup d'oeil.
J'ai créé ceci basé sur l'entrée de ce fil. Je dois utiliser odict cependant, donc je devais annuler get et set attr. Je pense que cela devrait fonctionner pour la majorité des utilisations spéciales.
L'utilisation ressemble à ceci:
# Create an ordered dict normally...
>>> od = OrderedAttrDict()
>>> od["a"] = 1
>>> od["b"] = 2
>>> od
OrderedAttrDict([('a', 1), ('b', 2)])
# Get and set data using attribute access...
>>> od.a
1
>>> od.b = 20
>>> od
OrderedAttrDict([('a', 1), ('b', 20)])
# Setting a NEW attribute only creates it on the instance, not the dict...
>>> od.c = 8
>>> od
OrderedAttrDict([('a', 1), ('b', 20)])
>>> od.c
8
La classe:
class OrderedAttrDict(odict.OrderedDict):
"""
Constructs an odict.OrderedDict with attribute access to data.
Setting a NEW attribute only creates it on the instance, not the dict.
Setting an attribute that is a key in the data will set the dict data but
will not create a new instance attribute
"""
def __getattr__(self, attr):
"""
Try to get the data. If attr is not a key, fall-back and get the attr
"""
if self.has_key(attr):
return super(OrderedAttrDict, self).__getitem__(attr)
else:
return super(OrderedAttrDict, self).__getattr__(attr)
def __setattr__(self, attr, value):
"""
Try to set the data. If attr is not a key, fall-back and set the attr
"""
if self.has_key(attr):
super(OrderedAttrDict, self).__setitem__(attr, value)
else:
super(OrderedAttrDict, self).__setattr__(attr, value)
C'est un modèle plutôt cool déjà mentionné dans le fil de discussion, mais si vous voulez juste prendre un dict et le convertir en un objet qui fonctionne avec l'auto-complétion dans un IDE, etc.:
class ObjectFromDict(object):
def __init__(self, d):
self.__dict__ = d
Pas besoin d'écrire votre propre comme setattr () et getattr () existent déjà.
L'avantage des objets de classe entre probablement en jeu dans la définition de la classe et l'héritage.
Juste pour ajouter de la variété à la réponse, sci-kit learn a ceci implémenté en tant que Bunch:
class Bunch(dict):
""" Scikit Learn's container object
Dictionary-like object that exposes its keys as attributes.
>>> b = Bunch(a=1, b=2)
>>> b['b']
2
>>> b.b
2
>>> b.c = 6
>>> b['c']
6
"""
def __init__(self, **kwargs):
super(Bunch, self).__init__(kwargs)
def __setattr__(self, key, value):
self[key] = value
def __dir__(self):
return self.keys()
def __getattr__(self, key):
try:
return self[key]
except KeyError:
raise AttributeError(key)
def __setstate__(self, state):
pass
Tout ce dont vous avez besoin est d’obtenir les méthodes setattr et getattr - la getattr vérifie les clés dict et passe à la recherche des attributs réels. setstaet est un correctif pour résoudre les problèmes de pickling/unpickling -/si intéressé/ https://github.com/scikit-learn/scikit-learn/issues/6196
Permettez-moi de publier une autre implémentation, qui repose sur la réponse de Kinvais, mais intègre les idées de AttributeDict proposé dans http://databio.org/posts/python_AttributeDict.html .
L'avantage de cette version est que cela fonctionne aussi pour les dictionnaires imbriqués:
class AttrDict(dict):
"""
A class to convert a nested Dictionary into an object with key-values
that are accessible using attribute notation (AttrDict.attribute) instead of
key notation (Dict["key"]). This class recursively sets Dicts to objects,
allowing you to recurse down nested dicts (like: AttrDict.attr.attr)
"""
# Inspired by:
# http://stackoverflow.com/a/14620633/1551810
# http://databio.org/posts/python_AttributeDict.html
def __init__(self, iterable, **kwargs):
super(AttrDict, self).__init__(iterable, **kwargs)
for key, value in iterable.items():
if isinstance(value, dict):
self.__dict__[key] = AttrDict(value)
else:
self.__dict__[key] = value
class AttrDict(dict):
def __init__(self):
self.__dict__ = self
if __== '____main__':
d = AttrDict()
d['ray'] = 'hope'
d.Sun = 'shine' >>> Now we can use this . notation
print d['ray']
print d.Sun
Vous pouvez utiliser dict_to_obj https://pypi.org/project/dict-to-obj/ Il fait exactement ce que vous avez demandé
From dict_to_obj import DictToObj
a = {
'foo': True
}
b = DictToObj(a)
b.foo
True
La solution est:
DICT_RESERVED_KEYS = vars(dict).keys()
class SmartDict(dict):
"""
A Dict which is accessible via attribute dot notation
"""
def __init__(self, *args, **kwargs):
"""
:param args: multiple dicts ({}, {}, ..)
:param kwargs: arbitrary keys='value'
If ``keyerror=False`` is passed then not found attributes will
always return None.
"""
super(SmartDict, self).__init__()
self['__keyerror'] = kwargs.pop('keyerror', True)
[self.update(arg) for arg in args if isinstance(arg, dict)]
self.update(kwargs)
def __getattr__(self, attr):
if attr not in DICT_RESERVED_KEYS:
if self['__keyerror']:
return self[attr]
else:
return self.get(attr)
return getattr(self, attr)
def __setattr__(self, key, value):
if key in DICT_RESERVED_KEYS:
raise AttributeError("You cannot set a reserved name as attribute")
self.__setitem__(key, value)
def __copy__(self):
return self.__class__(self)
def copy(self):
return self.__copy__()
Comme l'a noté Doug, il existe un paquet Bunch que vous pouvez utiliser pour obtenir la fonctionnalité obj.key. En fait, il existe une version plus récente appelée
Il possède cependant une fonctionnalité intéressante permettant de convertir votre dict en objet NeoBunch via sa fonction neobunchify. J'utilise beaucoup les modèles Mako et transmettre des données sous forme d'objets NeoBunch les rend beaucoup plus lisibles. Par conséquent, si vous finissez par utiliser un dict normal dans votre programme Python tout en voulant la notation par points dans un modèle Mako, vous pouvez l'utiliser:
from mako.template import Template
from neobunch import neobunchify
mako_template = Template(filename='mako.tmpl', strict_undefined=True)
data = {'tmpl_data': [{'key1': 'value1', 'key2': 'value2'}]}
with open('out.txt', 'w') as out_file:
out_file.write(mako_template.render(**neobunchify(data)))
Et le modèle Mako pourrait ressembler à:
% for d in tmpl_data:
Column1 Column2
${d.key1} ${d.key2}
% endfor
Vous pouvez le faire en utilisant ce cours que je viens de faire. Avec cette classe, vous pouvez utiliser l'objet Map comme un autre dictionnaire (y compris la sérialisation json) ou avec la notation par points. J'espère vous aider:
class Map(dict):
"""
Example:
m = Map({'first_name': 'Eduardo'}, last_name='Pool', age=24, sports=['Soccer'])
"""
def __init__(self, *args, **kwargs):
super(Map, self).__init__(*args, **kwargs)
for arg in args:
if isinstance(arg, dict):
for k, v in arg.iteritems():
self[k] = v
if kwargs:
for k, v in kwargs.iteritems():
self[k] = v
def __getattr__(self, attr):
return self.get(attr)
def __setattr__(self, key, value):
self.__setitem__(key, value)
def __setitem__(self, key, value):
super(Map, self).__setitem__(key, value)
self.__dict__.update({key: value})
def __delattr__(self, item):
self.__delitem__(item)
def __delitem__(self, key):
super(Map, self).__delitem__(key)
del self.__dict__[key]
Exemples d'utilisation:
m = Map({'first_name': 'Eduardo'}, last_name='Pool', age=24, sports=['Soccer'])
# Add new key
m.new_key = 'Hello world!'
print m.new_key
print m['new_key']
# Update values
m.new_key = 'Yay!'
# Or
m['new_key'] = 'Yay!'
# Delete key
del m.new_key
# Or
del m['new_key']
C'est ce que j'utilise
args = {
'batch_size': 32,
'workers': 4,
'train_dir': 'train',
'val_dir': 'val',
'lr': 1e-3,
'momentum': 0.9,
'weight_decay': 1e-4
}
args = namedtuple('Args', ' '.join(list(args.keys())))(**args)
print (args.lr)
Ce n’est pas une bonne réponse, mais j’ai pensé que c’était chouette (cela ne gère pas les dict imbriqués dans leur forme actuelle). Enveloppez simplement votre dict dans une fonction:
def make_funcdict(d={}, **kwargs)
def funcdict(d={}, **kwargs):
funcdict.__dict__.update(d)
funcdict.__dict__.update(kwargs)
return funcdict.__dict__
funcdict(d, **kwargs)
return funcdict
Maintenant, vous avez une syntaxe légèrement différente. f.key pour accéder aux éléments dict en tant qu'attributs. Pour accéder aux éléments dict (et aux autres méthodes dict) de la manière habituelle, faites f()['key'] et nous pouvons facilement mettre à jour le dict en appelant f avec des arguments de mots clés et/ou un dictionnaire.
Exemple
d = {'name':'Henry', 'age':31}
d = make_funcdict(d)
>>> for key in d():
... print key
...
age
name
>>> print d.name
... Henry
>>> print d.age
... 31
>>> d({'Height':'5-11'}, Job='Carpenter')
... {'age': 31, 'name': 'Henry', 'Job': 'Carpenter', 'Height': '5-11'}
Et voilà. Je serai heureux si quelqu'un suggère des avantages et des inconvénients de cette méthode.
Quelles seraient les mises en garde et les pièges pour accéder aux clés de dict de cette manière?
Comme @Henry le suggère, l'une des raisons pour lesquelles l'accès par points ne peut pas être utilisé dans dict est qu'il limite les noms de clés dict aux variables valides python, limitant ainsi tous les noms possibles.
Voici des exemples sur les raisons pour lesquelles l'accès par point ne serait pas utile en général, étant donné un dict, d:
Validité
Les attributs suivants ne seraient pas valides en Python:
d.1_foo # enumerated names
d./bar # path names
d.21.7, d.12:30 # decimals, time
d."" # empty strings
d.john doe, d.denny's # spaces, misc punctuation
d.3 * x # expressions
Style
Les conventions PEP8 imposeraient une contrainte douce à la désignation d'attribut:
A. Noms réservés mot clé (ou fonction intégrée):
d.in
d.False, d.True
d.max, d.min
d.sum
d.id
Si le nom d'un argument de fonction entre en conflit avec un mot clé réservé, il est généralement préférable d'ajouter un seul soulignement de fin ...
B. La règle de cas sur méthodes et noms de variables :
Les noms de variable suivent la même convention que les noms de fonction.
d.Firstname
d.Country
Utilisez les règles de dénomination de la fonction: minuscules avec des mots séparés par des tirets bas si nécessaire pour améliorer la lisibilité.
Parfois, ces préoccupations sont soulevées dans des bibliothèques telles que pandas , qui permet un accès en pointillé des colonnes DataFrame par leur nom. Le mécanisme par défaut pour résoudre les restrictions de dénomination est également la notation par tableau - une chaîne entre crochets.
Si ces contraintes ne s'appliquent pas à votre cas d'utilisation, plusieurs options sont disponibles sur structures de données en accès pointillé .