Aplatissement d'une liste peu profonde dans Python
Existe-t-il un moyen simple d'aplatir une liste d'itables avec une compréhension de liste, ou à défaut, que considéreriez-vous tous comme le meilleur moyen d'aplatir une liste peu profonde comme celle-ci, en équilibrant performances et lisibilité?
J'ai essayé d'aplatir une telle liste avec une compréhension de liste imbriquée, comme ceci:
[image for image in menuitem for menuitem in list_of_menuitems]
Mais j’ai des problèmes avec la variété NameError ici, parce que le name 'menuitem' is not defined. Après avoir cherché Google et regardé autour de Stack Overflow, j'ai obtenu les résultats souhaités avec une instruction reduce:
reduce(list.__add__, map(lambda x: list(x), list_of_menuitems))
Mais cette méthode est assez illisible car j’ai besoin de cet appel list(x) car x est un objet Django QuerySet.
Conclusion :
Merci à tous ceux qui ont contribué à cette question. Voici un résumé de ce que j'ai appris. Je fais aussi de ce wiki une communauté au cas où d'autres voudraient ajouter ou corriger ces observations.
Ma déclaration de réduction initiale est redondante et s’écrit mieux:
>>> reduce(list.__add__, (list(mi) for mi in list_of_menuitems))
C'est la syntaxe correcte pour une compréhension de liste imbriquée (Résumé Brilliant dF !):
>>> [image for mi in list_of_menuitems for image in mi]
Mais aucune de ces méthodes n'est aussi efficace que d'utiliser itertools.chain:
>>> from itertools import chain
>>> list(chain(*list_of_menuitems))
Et comme le note @cdleary, il vaut probablement mieux éviter le * magie de l'opérateur en utilisant chain.from_iterable comme suit:
>>> chain = itertools.chain.from_iterable([[1,2],[3],[5,89],[],[6]])
>>> print(list(chain))
>>> [1, 2, 3, 5, 89, 6]
Si vous souhaitez simplement parcourir une version aplatie de la structure de données et n'avez pas besoin d'une séquence indexable, considérez itertools.chain and company .
>>> list_of_menuitems = [['image00', 'image01'], ['image10'], []]
>>> import itertools
>>> chain = itertools.chain(*list_of_menuitems)
>>> print(list(chain))
['image00', 'image01', 'image10']
Cela fonctionnera sur tout ce qui est itérable, ce qui devrait inclure l'itérable QuerySets de Django, que vous utilisez apparemment dans la question.
Éditer: C'est probablement aussi bon que réduire, car réduction aura le même coût pour copier les éléments dans la liste en cours d'extension. chain n'entraînera cette surcharge que si vous exécutez list(chain) à la fin.
Méta-édition: En réalité, il s’agit de moins de frais généraux que la solution proposée par la question, car vous jetez les listes temporaires que vous avez créées lorsque vous étendez l’original avec la valeur temporaire. .
Edit: Comme dit JF Sebastianitertools.chain.from_iterable évite le déballage et vous devriez l'utiliser pour éviter * magique, mais l'application timeit montre une différence de performances négligeable.
Vous l'avez presque! Le façon de faire des compréhensions de liste imbriquée consiste à mettre les instructions for dans le même ordre qu’elles iraient dans des instructions imbriquées for régulières.
Ainsi, cette
for inner_list in outer_list:
for item in inner_list:
...
correspond à
[... for inner_list in outer_list for item in inner_list]
Alors vous voulez
[image for menuitem in list_of_menuitems for image in menuitem]
@ S.Lott : Vous m'avez inspiré pour écrire une application timeit.
Je pensais que cela varierait également en fonction du nombre de partitions (nombre d'itérateurs dans la liste des conteneurs) - votre commentaire ne mentionnait pas le nombre de partitions sur les trente éléments. Cette parcelle aplatit un millier d'éléments à chaque exécution, avec un nombre variable de partitions. Les éléments sont répartis uniformément entre les partitions.
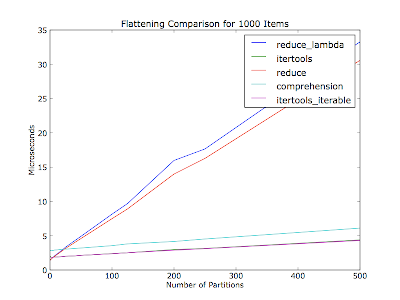
Code (Python 2.6):
#!/usr/bin/env python2.6
"""Usage: %prog item_count"""
from __future__ import print_function
import collections
import itertools
import operator
from timeit import Timer
import sys
import matplotlib.pyplot as pyplot
def itertools_flatten(iter_lst):
return list(itertools.chain(*iter_lst))
def itertools_iterable_flatten(iter_iter):
return list(itertools.chain.from_iterable(iter_iter))
def reduce_flatten(iter_lst):
return reduce(operator.add, map(list, iter_lst))
def reduce_lambda_flatten(iter_lst):
return reduce(operator.add, map(lambda x: list(x), [i for i in iter_lst]))
def comprehension_flatten(iter_lst):
return list(item for iter_ in iter_lst for item in iter_)
METHODS = ['itertools', 'itertools_iterable', 'reduce', 'reduce_lambda',
'comprehension']
def _time_test_assert(iter_lst):
"""Make sure all methods produce an equivalent value.
:raise AssertionError: On any non-equivalent value."""
callables = (globals()[method + '_flatten'] for method in METHODS)
results = [callable(iter_lst) for callable in callables]
if not all(result == results[0] for result in results[1:]):
raise AssertionError
def time_test(partition_count, item_count_per_partition, test_count=10000):
"""Run flatten methods on a list of :param:`partition_count` iterables.
Normalize results over :param:`test_count` runs.
:return: Mapping from method to (normalized) microseconds per pass.
"""
iter_lst = [[dict()] * item_count_per_partition] * partition_count
print('Partition count: ', partition_count)
print('Items per partition:', item_count_per_partition)
_time_test_assert(iter_lst)
test_str = 'flatten(%r)' % iter_lst
result_by_method = {}
for method in METHODS:
setup_str = 'from test import %s_flatten as flatten' % method
t = Timer(test_str, setup_str)
per_pass = test_count * t.timeit(number=test_count) / test_count
print('%20s: %.2f usec/pass' % (method, per_pass))
result_by_method[method] = per_pass
return result_by_method
if __== '__main__':
if len(sys.argv) != 2:
raise ValueError('Need a number of items to flatten')
item_count = int(sys.argv[1])
partition_counts = []
pass_times_by_method = collections.defaultdict(list)
for partition_count in xrange(1, item_count):
if item_count % partition_count != 0:
continue
items_per_partition = item_count / partition_count
result_by_method = time_test(partition_count, items_per_partition)
partition_counts.append(partition_count)
for method, result in result_by_method.iteritems():
pass_times_by_method[method].append(result)
for method, pass_times in pass_times_by_method.iteritems():
pyplot.plot(partition_counts, pass_times, label=method)
pyplot.legend()
pyplot.title('Flattening Comparison for %d Items' % item_count)
pyplot.xlabel('Number of Partitions')
pyplot.ylabel('Microseconds')
pyplot.show()
Edit: Décidé de faire de ce wiki une communauté.
Remarque: METHODS devrait probablement être cumulé avec un décorateur, mais je pense qu'il serait plus facile pour les gens de lire de cette façon.
sum(list_of_lists, []) l'aplatirait.
l = [['image00', 'image01'], ['image10'], []]
print sum(l,[]) # prints ['image00', 'image01', 'image10']
Cette solution fonctionne pour les profondeurs d'imbrication arbitraires - pas seulement la profondeur de "liste de listes" à laquelle certaines (toutes?) Des autres solutions sont limitées:
def flatten(x):
result = []
for el in x:
if hasattr(el, "__iter__") and not isinstance(el, basestring):
result.extend(flatten(el))
else:
result.append(el)
return result
C'est la récursion qui permet l'imbrication arbitraire de la profondeur - jusqu'à atteindre la profondeur de récursivité maximale, bien sûr ...
Dans Python2.6, en utilisant chain.from_iterable() :
>>> from itertools import chain
>>> list(chain.from_iterable(mi.image_set.all() for mi in h.get_image_menu()))
Cela évite de créer une liste intermédiaire.
Résultats de performance. Modifié.
import itertools
def itertools_flatten( aList ):
return list( itertools.chain(*aList) )
from operator import add
def reduce_flatten1( aList ):
return reduce(add, map(lambda x: list(x), [mi for mi in aList]))
def reduce_flatten2( aList ):
return reduce(list.__add__, map(list, aList))
def comprehension_flatten( aList ):
return list(y for x in aList for y in x)
J'ai mis à plat une liste de 30 éléments sur 2 niveaux 1000 fois
itertools_flatten 0.00554
comprehension_flatten 0.00815
reduce_flatten2 0.01103
reduce_flatten1 0.01404
Réduire est toujours un mauvais choix.
Il semble y avoir une confusion avec operator.add! Lorsque vous ajoutez deux listes ensemble, le terme correct pour cela est concat, pas add. operator.concat est ce que vous devez utiliser.
Si vous pensez fonctionnel, c'est aussi simple que cela:
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> reduce(operator.concat, list2d)
(1, 2, 3, 4, 5, 6, 7, 8, 9)
Vous voyez réduire respecte le type de séquence. Ainsi, lorsque vous fournissez un tuple, vous récupérez un tuple. Essayons avec une liste ::
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> reduce(operator.concat, list2d)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Aha, vous obtenez une liste.
Qu'en est-il de la performance ::
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> %timeit list(itertools.chain.from_iterable(list2d))
1000000 loops, best of 3: 1.36 µs per loop
from_iterable est assez rapide! Mais ce n'est pas une comparaison pour réduire avec concat.
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> %timeit reduce(operator.concat, list2d)
1000000 loops, best of 3: 492 ns per loop
De mémoire, vous pouvez éliminer le lambda:
reduce(list.__add__, map(list, [mi.image_set.all() for mi in list_of_menuitems]))
Ou même éliminer la carte, puisque vous avez déjà un list-comp:
reduce(list.__add__, [list(mi.image_set.all()) for mi in list_of_menuitems])
Vous pouvez aussi simplement exprimer ceci sous forme de somme de listes:
sum([list(mi.image_set.all()) for mi in list_of_menuitems], [])
Voici la solution correcte en utilisant les compréhensions de liste (elles sont arriérées dans la question):
>>> join = lambda it: (y for x in it for y in x)
>>> list(join([[1,2],[3,4,5],[]]))
[1, 2, 3, 4, 5]
Dans votre cas ce serait
[image for menuitem in list_of_menuitems for image in menuitem.image_set.all()]
ou vous pouvez utiliser join et dire
join(menuitem.image_set.all() for menuitem in list_of_menuitems)
Dans les deux cas, le gotcha était l’imbrication des boucles for.
Voici une version qui fonctionne pour plusieurs niveaux de liste en utilisant collectons.Iterable:
import collections
def flatten(o, flatten_condition=lambda i: isinstance(i,
collections.Iterable) and not isinstance(i, str)):
result = []
for i in o:
if flatten_condition(i):
result.extend(flatten(i, flatten_condition))
else:
result.append(i)
return result
Cette version est un générateur. Double-la si tu veux une liste.
def list_or_Tuple(l):
return isinstance(l,(list,Tuple))
## predicate will select the container to be flattened
## write your own as required
## this one flattens every list/Tuple
def flatten(seq,predicate=list_or_Tuple):
## recursive generator
for i in seq:
if predicate(seq):
for j in flatten(i):
yield j
else:
yield i
Vous pouvez ajouter un prédicat si vous voulez aplatir ceux qui remplissent une condition
Tiré de python livre de recettes
D'après mon expérience, le moyen le plus efficace d'aplanir une liste de listes est le suivant:
flat_list = []
map(flat_list.extend, list_of_list)
Quelques comparaisons dans le temps avec les autres méthodes proposées:
list_of_list = [range(10)]*1000
%timeit flat_list=[]; map(flat_list.extend, list_of_list)
#10000 loops, best of 3: 119 µs per loop
%timeit flat_list=list(itertools.chain.from_iterable(list_of_list))
#1000 loops, best of 3: 210 µs per loop
%timeit flat_list=[i for sublist in list_of_list for i in sublist]
#1000 loops, best of 3: 525 µs per loop
%timeit flat_list=reduce(list.__add__,list_of_list)
#100 loops, best of 3: 18.1 ms per loop
Maintenant, le gain d’efficacité apparaît mieux lors du traitement de sous-listes plus longues:
list_of_list = [range(1000)]*10
%timeit flat_list=[]; map(flat_list.extend, list_of_list)
#10000 loops, best of 3: 60.7 µs per loop
%timeit flat_list=list(itertools.chain.from_iterable(list_of_list))
#10000 loops, best of 3: 176 µs per loop
Et cette méthode fonctionne aussi avec n'importe quel objet itératif:
class SquaredRange(object):
def __init__(self, n):
self.range = range(n)
def __iter__(self):
for i in self.range:
yield i**2
list_of_list = [SquaredRange(5)]*3
flat_list = []
map(flat_list.extend, list_of_list)
print flat_list
#[0, 1, 4, 9, 16, 0, 1, 4, 9, 16, 0, 1, 4, 9, 16]
Si vous avez à plat une liste plus compliquée avec des éléments non-itérables ou avec une profondeur supérieure à 2, vous pouvez utiliser la fonction suivante:
def flat_list(list_to_flat):
if not isinstance(list_to_flat, list):
yield list_to_flat
else:
for item in list_to_flat:
yield from flat_list(item)
Il retournera un objet générateur que vous pourrez convertir en liste avec la fonction list(). Notez que la syntaxe yield from est disponible à partir de python3.3, mais vous pouvez utiliser une itération explicite à la place.
Exemple:
>>> a = [1, [2, 3], [1, [2, 3, [1, [2, 3]]]]]
>>> print(list(flat_list(a)))
[1, 2, 3, 1, 2, 3, 1, 2, 3]
avez-vous essayé aplatir? De matplotlib.cbook.flatten (seq, scalarp =) ?
l=[[1,2,3],[4,5,6], [7], [8,9]]*33
run("list(flatten(l))")
3732 function calls (3303 primitive calls) in 0.007 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.007 0.007 <string>:1(<module>)
429 0.001 0.000 0.001 0.000 cbook.py:475(iterable)
429 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like)
429 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string)
727/298 0.001 0.000 0.007 0.000 cbook.py:605(flatten)
429 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray)
858 0.001 0.000 0.001 0.000 {isinstance}
429 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*66
run("list(flatten(l))")
7461 function calls (6603 primitive calls) in 0.007 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.007 0.007 <string>:1(<module>)
858 0.001 0.000 0.001 0.000 cbook.py:475(iterable)
858 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like)
858 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string)
1453/595 0.001 0.000 0.007 0.000 cbook.py:605(flatten)
858 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray)
1716 0.001 0.000 0.001 0.000 {isinstance}
858 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*99
run("list(flatten(l))")
11190 function calls (9903 primitive calls) in 0.010 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.010 0.010 <string>:1(<module>)
1287 0.002 0.000 0.002 0.000 cbook.py:475(iterable)
1287 0.003 0.000 0.004 0.000 cbook.py:484(is_string_like)
1287 0.002 0.000 0.009 0.000 cbook.py:565(is_scalar_or_string)
2179/892 0.001 0.000 0.010 0.000 cbook.py:605(flatten)
1287 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray)
2574 0.001 0.000 0.001 0.000 {isinstance}
1287 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*132
run("list(flatten(l))")
14919 function calls (13203 primitive calls) in 0.013 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.013 0.013 <string>:1(<module>)
1716 0.002 0.000 0.002 0.000 cbook.py:475(iterable)
1716 0.004 0.000 0.006 0.000 cbook.py:484(is_string_like)
1716 0.003 0.000 0.011 0.000 cbook.py:565(is_scalar_or_string)
2905/1189 0.002 0.000 0.013 0.000 cbook.py:605(flatten)
1716 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray)
3432 0.001 0.000 0.001 0.000 {isinstance}
1716 0.001 0.000 0.001 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler'
UPDATE Ce qui m'a donné une autre idée:
l=[[1,2,3],[4,5,6], [7], [8,9]]*33
run("flattenlist(l)")
564 function calls (432 primitive calls) in 0.000 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
133/1 0.000 0.000 0.000 0.000 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
429 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*66
run("flattenlist(l)")
1125 function calls (861 primitive calls) in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
265/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
858 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*99
run("flattenlist(l)")
1686 function calls (1290 primitive calls) in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
397/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
1287 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*132
run("flattenlist(l)")
2247 function calls (1719 primitive calls) in 0.002 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
529/1 0.001 0.000 0.002 0.002 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.002 0.002 <string>:1(<module>)
1716 0.001 0.000 0.001 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*1320
run("flattenlist(l)")
22443 function calls (17163 primitive calls) in 0.016 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
5281/1 0.011 0.000 0.016 0.016 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.016 0.016 <string>:1(<module>)
17160 0.005 0.000 0.005 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
Donc, pour tester son efficacité quand la récursive devient plus profonde: combien plus profonde?
l=[[1,2,3],[4,5,6], [7], [8,9]]*1320
new=[l]*33
run("flattenlist(new)")
740589 function calls (566316 primitive calls) in 0.418 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
174274/1 0.281 0.000 0.417 0.417 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.001 0.001 0.418 0.418 <string>:1(<module>)
566313 0.136 0.000 0.136 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*66
run("flattenlist(new)")
1481175 function calls (1132629 primitive calls) in 0.809 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
348547/1 0.542 0.000 0.807 0.807 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.002 0.002 0.809 0.809 <string>:1(<module>)
1132626 0.266 0.000 0.266 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*99
run("flattenlist(new)")
2221761 function calls (1698942 primitive calls) in 1.211 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
522820/1 0.815 0.000 1.208 1.208 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.002 0.002 1.211 1.211 <string>:1(<module>)
1698939 0.393 0.000 0.393 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*132
run("flattenlist(new)")
2962347 function calls (2265255 primitive calls) in 1.630 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
697093/1 1.091 0.000 1.627 1.627 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.003 0.003 1.630 1.630 <string>:1(<module>)
2265252 0.536 0.000 0.536 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*1320
run("flattenlist(new)")
29623443 function calls (22652523 primitive calls) in 16.103 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
6970921/1 10.842 0.000 16.069 16.069 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.034 0.034 16.103 16.103 <string>:1(<module>)
22652520 5.227 0.000 5.227 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
Je parie que "flattenlist" je vais utiliser cela plutôt que matploblib pendant un long moment sauf si je veux un générateur de rendement et un résultat rapide car "flatten" utilise dans matploblib.cbook
C'est rapide.
- Et voici le code
:
typ=(list,Tuple)
def flattenlist(d):
thelist = []
for x in d:
if not isinstance(x,typ):
thelist += [x]
else:
thelist += flattenlist(x)
return thelist
def is_iterable(item):
return isinstance(item, list) or isinstance(item, Tuple)
def flatten(items):
for i in items:
if is_iterable(item):
for m in flatten(i):
yield m
else:
yield i
Tester:
print list(flatten2([1.0, 2, 'a', (4,), ((6,), (8,)), (((8,),(9,)), ((12,),(10)))]))
pylab fournit un aplatissement: lien vers numpy aplatir
Si vous recherchez une solution simple, intégrée et intégrée, vous pouvez utiliser:
a = [[1, 2, 3], [4, 5, 6]
b = [i[x] for i in a for x in range(len(i))]
print b
résultats
[1, 2, 3, 4, 5, 6]
Qu'en est-il de:
from operator import add
reduce(add, map(lambda x: list(x.image_set.all()), [mi for mi in list_of_menuitems]))
Mais Guido recommande de ne pas trop exécuter dans une seule ligne de code car cela réduit la lisibilité. Le gain de performances est minime, voire nul, en effectuant ce que vous voulez sur une seule ligne plutôt que sur plusieurs lignes.
Si chaque élément de la liste est une chaîne (et que toutes les chaînes contenues dans ces chaînes utilisent "" plutôt que ''), vous pouvez utiliser des expressions régulières (module re).
>>> flattener = re.compile("\'.*?\'")
>>> flattener
<_sre.SRE_Pattern object at 0x10d439ca8>
>>> stred = str(in_list)
>>> outed = flattener.findall(stred)
Le code ci-dessus convertit in_list en chaîne, utilise l’expression rationnelle pour rechercher toutes les sous-chaînes entre guillemets (c’est-à-dire chaque élément de la liste) et les recrache sous forme de liste.
Une alternative simple consiste à utiliser concatenate de numpy mais le contenu est converti en float:
import numpy as np
print np.concatenate([[1,2],[3],[5,89],[],[6]])
# array([ 1., 2., 3., 5., 89., 6.])
print list(np.concatenate([[1,2],[3],[5,89],[],[6]]))
# [ 1., 2., 3., 5., 89., 6.]
Le moyen le plus simple d'y parvenir dans Python 2 ou 3 consiste à utiliser la bibliothèque morph à l'aide de pip install morph.
Le code est:
import morph
list = [[1,2],[3],[5,89],[],[6]]
flattened_list = morph.flatten(list) # returns [1, 2, 3, 5, 89, 6]
Dans Python 3.4 vous pourrez faire:
[*innerlist for innerlist in outer_list]