Quelle est la lenteur de la concaténation de chaînes de Python par rapport à str.join?
À la suite des commentaires de ma réponse sur ce fil , je voulais savoir quelle est la différence de vitesse entre l'opérateur += et ''.join().
Alors, quelle est la comparaison de vitesse entre les deux?
De: Concurrence efficace des chaînes
Méthode 1:
def method1():
out_str = ''
for num in xrange(loop_count):
out_str += 'num'
return out_str
Méthode 4:
def method4():
str_list = []
for num in xrange(loop_count):
str_list.append('num')
return ''.join(str_list)
Maintenant, je réalise qu'ils ne sont pas strictement représentatifs, et la 4ème méthode est ajoutée à une liste avant de parcourir et de joindre chaque élément, mais c'est une indication juste.
La jointure de chaînes est nettement plus rapide que la concaténation.
Pourquoi? Les chaînes sont immuables et ne peuvent pas être modifiées en place. Pour en modifier une, une nouvelle représentation doit être créée (une concaténation des deux).
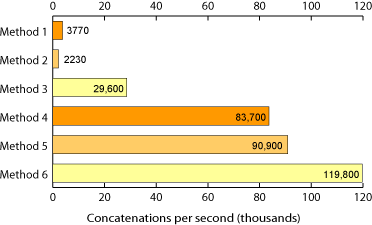
Mon code original était faux, il semble que la concaténation + soit généralement plus rapide (en particulier avec les versions plus récentes de Python sur du matériel plus récent).
Les temps sont les suivants:
Iterations: 1,000,000
Python 3.3 sur Windows 7, Core i7
String of len: 1 took: 0.5710 0.2880 seconds
String of len: 4 took: 0.9480 0.5830 seconds
String of len: 6 took: 1.2770 0.8130 seconds
String of len: 12 took: 2.0610 1.5930 seconds
String of len: 80 took: 10.5140 37.8590 seconds
String of len: 222 took: 27.3400 134.7440 seconds
String of len: 443 took: 52.9640 170.6440 seconds
Python 2.7 sur Windows 7, Core i7
String of len: 1 took: 0.7190 0.4960 seconds
String of len: 4 took: 1.0660 0.6920 seconds
String of len: 6 took: 1.3300 0.8560 seconds
String of len: 12 took: 1.9980 1.5330 seconds
String of len: 80 took: 9.0520 25.7190 seconds
String of len: 222 took: 23.1620 71.3620 seconds
String of len: 443 took: 44.3620 117.1510 seconds
Sous Linux Mint, Python 2.7, un processeur plus lent
String of len: 1 took: 1.8840 1.2990 seconds
String of len: 4 took: 2.8394 1.9663 seconds
String of len: 6 took: 3.5177 2.4162 seconds
String of len: 12 took: 5.5456 4.1695 seconds
String of len: 80 took: 27.8813 19.2180 seconds
String of len: 222 took: 69.5679 55.7790 seconds
String of len: 443 took: 135.6101 153.8212 seconds
Et voici le code:
from __future__ import print_function
import time
def strcat(string):
newstr = ''
for char in string:
newstr += char
return newstr
def listcat(string):
chars = []
for char in string:
chars.append(char)
return ''.join(chars)
def test(fn, times, *args):
start = time.time()
for x in range(times):
fn(*args)
return "{:>10.4f}".format(time.time() - start)
def testall():
strings = ['a', 'long', 'longer', 'a bit longer',
'''adjkrsn widn fskejwoskemwkoskdfisdfasdfjiz oijewf sdkjjka dsf sdk siasjk dfwijs''',
'''this is a really long string that's so long
it had to be triple quoted and contains lots of
superflous characters for kicks and gigles
@!#(*_#)(*$(*!#@&)(*E\xc4\x32\xff\x92\x23\xDF\xDFk^%#$!)%#^(*#''',
'''I needed another long string but this one won't have any new lines or crazy characters in it, I'm just going to type normal characters that I would usually write blah blah blah blah this is some more text hey cool what's crazy is that it looks that the str += is really close to the O(n^2) worst case performance, but it looks more like the other method increases in a perhaps linear scale? I don't know but I think this is enough text I hope.''']
for string in strings:
print("String of len:", len(string), "took:", test(listcat, 1000000, string), test(strcat, 1000000, string), "seconds")
testall()
Les réponses existantes sont très bien écrites et ont fait l'objet de recherches, mais voici une autre réponse pour l'ère Python 3.6, car nous disposons maintenant de interpolation de chaîne littérale (AKA, f- strings):
>>> import timeit
>>> timeit.timeit('f\'{"a"}{"b"}{"c"}\'', number=1000000)
0.14618930302094668
>>> timeit.timeit('"".join(["a", "b", "c"])', number=1000000)
0.23334730707574636
>>> timeit.timeit('a = "a"; a += "b"; a += "c"', number=1000000)
0.14985873899422586
Test effectué à l'aide de CPython 3.6.5 sur un MacBook Pro Retina 2012 doté d'un processeur Intel Core i7 à 2,3 GHz.
Il ne s’agit en aucun cas d’une référence formelle, mais il semble que l’utilisation de chaînes f- est à peu près aussi performante que la concaténation +=; toute amélioration des mesures ou des suggestions est bien sûr bienvenue.
J'ai réécrit la dernière réponse, pourriez-vous s'il vous plaît partager votre opinion sur la façon dont j'ai testé?
import time
start1 = time.clock()
for x in range (10000000):
dog1 = ' and '.join(['spam', 'eggs', 'spam', 'spam', 'eggs', 'spam','spam', 'eggs', 'spam', 'spam', 'eggs', 'spam'])
end1 = time.clock()
print("Time to run Joiner = ", end1 - start1, "seconds")
start2 = time.clock()
for x in range (10000000):
dog2 = 'spam'+' and '+'eggs'+' and '+'spam'+' and '+'spam'+' and '+'eggs'+' and '+'spam'+' and '+'spam'+' and '+'eggs'+' and '+'spam'+' and '+'spam'+' and '+'eggs'+' and '+'spam'
end2 = time.clock()
print("Time to run + = ", end2 - start2, "seconds")
REMARQUE: Cet exemple est écrit en Python 3.5, où range () agit comme l'ancien xrange ().
Le résultat obtenu:
Time to run Joiner = 27.086106206103153 seconds
Time to run + = 69.79100515996426 seconds
Personnellement, je préfère '' .join ([]) à la 'méthode Plusser' car elle est plus propre et plus lisible.
C'est ce que les programmes idiots sont conçus pour tester :)
Utilisez plus
import time
if __== '__main__':
start = time.clock()
for x in range (1, 10000000):
dog = "a" + "b"
end = time.clock()
print "Time to run Plusser = ", end - start, "seconds"
Sortie de:
Time to run Plusser = 1.16350010965 seconds
Maintenant avec rejoindre ....
import time
if __== '__main__':
start = time.clock()
for x in range (1, 10000000):
dog = "a".join("b")
end = time.clock()
print "Time to run Joiner = ", end - start, "seconds"
Sortie de:
Time to run Joiner = 21.3877386651 seconds
Donc, sur Python 2.6 sur Windows, je dirais que + est environ 18 fois plus rapide que rejoindre :)