Qu'est-ce qu'une expression régulière qui correspond à un nom de domaine valide sans sous-domaine?
Tout d'abord désolé pour la 10 000e question RegEx,
Je me rends compte qu'il y a d'autres questions relatives au domaine, mais la regex ne fonctionne pas correctement, est trop complexe ou concerne les URL avec des sous-domaines, des protocoles et des chemins de fichiers.
Le mien est plus simple, je dois valider un nom de domaine:
google.com
stackoverflow.com
Donc, un domaine dans sa forme la plus crue - pas même un sous-domaine comme www.
- Les caractères ne doivent être que a-z | A-Z | -9 et période (.) Et tiret (-)
- La partie du nom de domaine ne doit pas commencer ni se terminer par un tiret (-) (par exemple, -google-.com)
- La partie du nom de domaine doit comporter entre 1 et 63 caractères
L'extension (TLD) peut être n'importe quoi selon les règles n ° 1 pour le moment, je pourrai les valider plus tard sur une liste, mais il devrait contenir un ou plusieurs caractères.
Edit: TLD est apparemment 2-6 caractères tel qu'il est
N ° 4 révisé: Le TLD devrait en fait s'appeler "sous-domaine" car il devrait inclure des éléments tels que .co.uk - J'imagine que la seule validation possible (hormis le contrôle sur une liste) serait ' après le premier point, il devrait y avoir un ou plusieurs caractères selon les règles n ° 1
Merci beaucoup, croyez-moi, j'ai essayé!
Eh bien c'est assez simple un peu plus sournois qu'il n'y paraît (voir commentaires), compte tenu de vos besoins spécifiques:
/^[a-zA-Z0-9][a-zA-Z0-9-]{1,61}[a-zA-Z0-9]\.[a-zA-Z]{2,}$/
Mais notez que cela rejettera beaucoup de domaines valides.
Je sais qu'il s'agit d'un vieux post, mais il manque à un seul composant très important dans les expressions régulières: la prise en charge des noms de domaine IDN.
noms de domaine IDN commencent par xn--. Ils activent les caractères UTF-8 étendus dans les noms de domaine. Par exemple, saviez-vous que "♡ .com" est un nom de domaine valide? Ouais, "love heart dot com"! Pour valider le nom de domaine, vous devez laisser http://xn--c6h.com/ passer la validation.
Notez que pour utiliser cette expression rationnelle, vous devez convertir le domaine en minuscules et utiliser une bibliothèque IDN pour vous assurer de coder les noms de domaine en ACE (également appelé "codage compatible ASCII"). Une bonne bibliothèque est GNU-Libidn.
idn (1) est l'interface de ligne de commande de la bibliothèque de noms de domaine internationalisée. L'exemple suivant convertit le nom d'hôte UTF-8 en codage ACE. L'URL résultante https: //nic.xn--flw351e/ peut ensuite être utilisée en tant qu'équivalent codé par l'ACE de https: // nic. 歌 / .
$ idn --quiet -a nic.谷歌
nic.xn--flw351e
Cette expression régulière magique devrait couvrir la plupart domaines (même si, je suis sûr qu'il y a beaucoup de cas Edge valides que j'ai manqués):
^((?!-))(xn--)?[a-z0-9][a-z0-9-_]{0,61}[a-z0-9]{0,1}\.(xn--)?([a-z0-9\-]{1,61}|[a-z0-9-]{1,30}\.[a-z]{2,})$
Lorsque vous choisissez une expression rationnelle de validation de domaine, vous devriez voir si le domaine correspond aux éléments suivants:
- xn--stackoverflow.com
- stackoverflow.xn - com
- stackoverflow.co.uk
Si ces trois domaines ne passent pas, votre expression régulière n'autorisera peut-être pas les domaines légitimes!
Consultez la section page Internationalized Domain Names Support du International Language Environment Guide d’Oracle pour plus d’informations.
N'hésitez pas à essayer le regex ici: http://www.regexr.com/3abjr
ICANN conserve ne liste de tlds qui ont été délégués qui peuvent être utilisés pour voir quelques exemples de domaines IDN.
Modifier:
^(((?!-))(xn--|_{1,1})?[a-z0-9-]{0,61}[a-z0-9]{1,1}\.)*(xn--)?([a-z0-9][a-z0-9\-]{0,60}|[a-z0-9-]{1,30}\.[a-z]{2,})$
Cette expression régulière arrêtera les domaines dont le nom '-' à la fin du nom d'hôte est marqué comme étant valide. De plus, il permet un nombre illimité de sous-domaines.
Mon RegEx est le suivant:
^[a-zA-Z0-9][a-zA-Z0-9-_]{0,61}[a-zA-Z0-9]{0,1}\.([a-zA-Z]{1,6}|[a-zA-Z0-9-]{1,30}\.[a-zA-Z]{2,3})$
c'est ok pour i.oh1.me et pour wow.british-library.uk
UPD
Voici la règle mise à jour
^(([a-zA-Z]{1})|([a-zA-Z]{1}[a-zA-Z]{1})|([a-zA-Z]{1}[0-9]{1})|([0-9]{1}[a-zA-Z]{1})|([a-zA-Z0-9][a-zA-Z0-9-_]{1,61}[a-zA-Z0-9]))\.([a-zA-Z]{2,6}|[a-zA-Z0-9-]{2,30}\.[a-zA-Z]{2,3})$
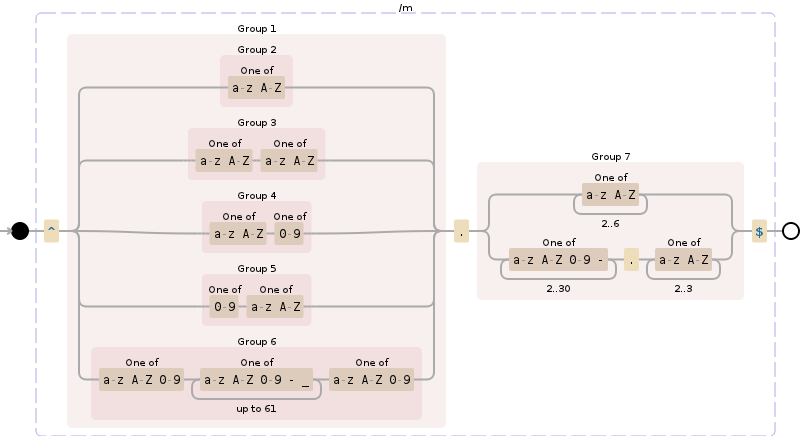
https://www.debuggex.com/r/y4Xe_hDVO11bv1DV
maintenant, il vérifie - ou _ dans le libellé de début ou de fin de domaine.
Mon pari:
^(?:[a-z0-9](?:[a-z0-9-]{0,61}[a-z0-9])?\.)+[a-z0-9][a-z0-9-]{0,61}[a-z0-9]$
Expliqué:
Le nom de domaine est construit à partir de segments. Voici un segment (sauf final):
[a-z0-9](?:[a-z0-9-]{0,61}[a-z0-9])?
Il peut avoir 1-63 caractères, ne commence ni ne finit par '-'.
Maintenant, ajoutez '.' et répétez au moins une fois:
(?:[a-z0-9](?:[a-z0-9-]{0,61}[a-z0-9])?\.)+
Puis attachez le dernier segment, composé de 2 à 63 caractères:
[a-z0-9][a-z0-9-]{0,61}[a-z0-9]
Testez-le ici: http://regexr.com/3au3g
Juste une correction mineure - la dernière partie devrait être jusqu'à 6. Par conséquent,
^[a-z0-9]+([\-\.]{1}[a-z0-9]+)*\.[a-z]{2,6}$
Le plus long TLD est museum (6 caractères) - http://en.wikipedia.org/wiki/List_of_Internet_top-level_domains
Réponse acceptée ne fonctionne pas pour moi, essayez ceci:
^ ((?! -) [A-Za-z0-9 -] {1,63} (? <! -) \.) + [A-Za-z] {2,6} $
Visitez this nit Test Case pour validation.
Cette réponse concerne les noms de domaine (y compris les RR de service), et non les noms d'hôte (comme un nom d'hôte de messagerie).
^(?=.{1,253}\.?$)(?:(?!-|[^.]+_)[A-Za-z0-9-_]{1,63}(?<!-)(?:\.|$)){2,}$
C'est fondamentalement réponse de mkyong et en plus:
- Longueur maximale de 255 octets, y compris les préfixes de longueur et la racine nulle.
- Autoriser la fuite '.' pour la racine DNS explicite.
- Autoriser les '_' en tête pour les RR de domaine de service, (bogues: n'applique pas 15 caractères maximum pour les étiquettes _, ni ne nécessite au moins un domaine supérieur aux RR de service)
- Correspond à tous les TLD possibles.
- Ne capture pas les étiquettes de sous-domaines.
Par pièces
Lookahead, limite la longueur maximale entre ^ $ à 253 caractères avec le littéral final optionnel '.'
(?=.{1,253}\.?$)
Lookahead, le caractère suivant n'est pas un '-' et aucun '_' ne suit aucun caractère avant le prochain '.'. C'est-à-dire que le premier caractère d'une étiquette n'est pas un '-' et que seul le premier caractère peut être un '_'.
(?!-|[^.]+_)
Entre 1 et 63 caractères autorisés par étiquette.
[A-Za-z0-9-_]{1,63}
Lookbehind, le caractère précédent n'est pas '-'. C'est-à-dire que le dernier caractère d'une étiquette n'est pas un '-'.
(?<!-)
Forcer un '.' à la fin de chaque étiquette sauf la dernière, où elle est facultative.
(?:\.|$)
Généralement combinés par le haut, cela nécessite au moins deux niveaux de domaine, ce qui n'est pas tout à fait correct, mais constitue généralement une hypothèse raisonnable. Passez de {2,} à + si vous souhaitez autoriser les TLD ou les sous-domaines relatifs non qualifiés via (par exemple, localhost, myrouter, to.)
(?:(?!-|[^.]+_)[A-Za-z0-9-_]{1,63}(?<!-)(?:\.|$)){2,}
Tests unitaires pour cette expression.
Merci d'avoir indiqué la bonne direction dans les solutions de validation de nom de domaine dans d'autres réponses. Les noms de domaine peuvent être validés de différentes manières.
Si vous devez valider IDN le domaine dans son forme lisible par l'homme , regex \p{L} aidera. Cela permet de faire correspondre n'importe quel caractère dans n'importe quelle langue.
Notez que la dernière partie peut aussi contenir des traits d'union ! En tant que punycode, les noms chinois peuvent avoir des caractères unicode dans tld.
Je suis venu à la solution qui correspondra par exemple:
- google.com
- masełkowski.pl
- maselkowski.pl
- m.maselkowski.pl
- www.masełkowski.pl.com
- xn--masekowski-d0b.pl
- 中国 互联 网络 信息 中心. 中国
- xn - fiqa61au8b7zsevnm8ak20mc4a87e.xn - fiqs8s
Regex est:
^[0-9\p{L}][0-9\p{L}-\.]{1,61}[0-9\p{L}]\.[0-9\p{L}][\p{L}-]*[0-9\p{L}]+$
NOTE: Cette expression rationnelle est assez permissive, de même que le jeu de caractères autorisé pour les noms de domaine actuels.
UPDATE: Encore plus simplifié, car a-aA-Z\p{L} est identique à \p{L}
NOTE2: Le seul problème est qu'il va faire correspondre les domaines avec des points doubles ..., comme masełk..owski.pl. Si quelqu'un sait comment résoudre ce problème, améliorez-le.
Pas assez de rep encore pour commenter. En réponse à la solution de paka, j'ai découvert que j'avais besoin d'ajuster trois éléments:
- Le tiret et le soulignement ont été déplacés car il était interprété comme une plage (comme dans "0-9")
- Ajout d'un arrêt complet pour les noms de domaine avec plusieurs sous-domaines
- Extension de la longueur potentielle des TLD à 13
Avant:
^(([a-zA-Z]{1})|([a-zA-Z]{1}[a-zA-Z]{1})|([a-zA-Z]{1}[0-9]{1})|([0-9]{1}[a-zA-Z]{1})|([a-zA-Z0-9][a-zA-Z0-9-_]{1,61}[a-zA-Z0-9]))\.([a-zA-Z]{2,6}|[a-zA-Z0-9-]{2,30}\.[a-zA-Z]{2,3})$
Après:
^(([a-zA-Z]{1})|([a-zA-Z]{1}[a-zA-Z]{1})|([a-zA-Z]{1}[0-9]{1})|([0-9]{1}[a-zA-Z]{1})|([a-zA-Z0-9][-_\.a-zA-Z0-9]{1,61}[a-zA-Z0-9]))\.([a-zA-Z]{2,13}|[a-zA-Z0-9-]{2,30}\.[a-zA-Z]{2,3})$
^[a-z0-9]+([\-\.]{1}[a-z0-9]+)*\.[a-z]{2,7}$
[domaine - lettres minuscules et 0-9 seulement] [peut avoir un trait d'union] + [TLD - minuscule seulement, doit être compris entre 2 et 7 lettres]
http://rubular.com/ est génial pour tester les expressions régulières!
Edit: TLD mis à jour, avec un maximum de 7 caractères pour '.rentals', comme l'a souligné Dan Caddigan.
^((localhost)|((?!-)[A-Za-z0-9-]{1,63}(?<!-)\.)+[A-Za-z]{2,253})$
Merci @mkyong pour la base de ma réponse. Je l'ai modifié pour prendre en charge les étiquettes acceptables plus longtemps.
En outre, "localhost" est techniquement un nom de domaine valide. Je modifierai cette réponse pour prendre en compte les noms de domaine internationalisés.
Pour les nouveaux gTLD
/^((?!-)[\p{L}\p{N}-]+(?<!-)\.)+[\p{L}\p{N}]{2,}$/iu
^[a-zA-Z0-9][a-zA-Z0-9-]{1,61}[a-zA-Z0-9]\.[a-zA-Z]+(\.[a-zA-Z]+)$
Voici le code complet avec exemple:
<?php
function is_domain($url)
{
$parse = parse_url($url);
if (isset($parse['Host'])) {
$domain = $parse['Host'];
} else {
$domain = $url;
}
return preg_match('/^(?!\-)(?:[a-zA-Z\d\-]{0,62}[a-zA-Z\d]\.){1,126}(?!\d+)[a-zA-Z\d]{1,63}$/', $domain);
}
echo is_domain('example.com'); //true
echo is_domain('https://example.com'); //true
echo is_domain('https://.example.com'); //false
echo is_domain('https://localhost'); //false
Comme déjà indiqué, il n'est pas évident de dire les sous-domaines dans le sens pratique. Nous utilisons cette regex pour valider les domaines qui se trouvent dans la nature. Il couvre tous les cas d'utilisation pratiques que je connaisse. Les nouveaux sont les bienvenus. Selon nos directives , cela évite les groupes non capturés et les correspondances gloutonnes.
^(?!.*?_.*?)(?!(?:[\d\w]+?\.)?\-[\w\d\.\-]*?)(?![\w\d]+?\-\.(?:[\d\w\.\-]+?))(?=[\w\d])(?=[\w\d\.\-]*?\.+[\w\d\.\-]*?)(?![\w\d\.\-]{254})(?!(?:\.?[\w\d\-\.]*?[\w\d\-]{64,}\.)+?)[\w\d\.\-]+?(?<![\w\d\-\.]*?\.[\d]+?)(?<=[\w\d\-]{2,})(?<![\w\d\-]{25})$
Preuve et explication: https://regex101.com/r/FLA9Bv/9
Vous avez le choix entre deux approches lors de la validation de domaines.
Correspondance par nom de domaine complet (définition théorique, rarement rencontrée dans la pratique):
- longueur maximale de 253 caractères (conformément à RFC-1035/3.1 , RFC-2181/11 )
- 63 caractères maximum par étiquette (conformément à RFC-1035/3.1 , RFC-2181/11 )
- tous les caractères sont autorisés (selon RFC-2181/11 )
- Les TLD ne peuvent pas être entièrement numériques (conformément à RFC-3696/2 )
- Les noms de domaine complets peuvent être écrits sous une forme complète, incluant la zone racine (le point final)
Correspondance FQDN pratique/conservative (définition pratique, attendue et prise en charge dans la pratique):
- par-the-books correspondant aux exceptions/ajouts suivants
- caractères valides:
[a-zA-Z0-9.-] - les étiquettes ne peuvent pas commencer ou se terminer par des traits d'union (conformément à RFC-952 et RFC-1123/2.1 )
- La longueur minimale de TLD est de 2 caractères, la longueur maximale est de 24 caractères selon les enregistrements existants.
- ne correspond pas au dernier point
^ [a-zA-Z0-9] [- a-zA-Z0-9] + [a-zA-Z0-9]. [az] {2,3} (. [az] {2,3}) ? (. [az] {2,3})? $
Des exemples qui fonctionnent:
stack.com
sta-ck.com
sta---ck.com
9sta--ck.com
sta--ck9.com
stack99.com
99stack.com
sta99ck.com
Cela fonctionnera également pour les extensions
.com.uk
.co.in
.uk.edu.in
Exemples qui ne fonctionneront pas:
-stack.com
cela fonctionnera même avec l'extension de domaine la plus longue ".versicherung"
/^((([a-zA-Z]{1,2})|([0-9]{1,2})|([a-zA-Z0-9]{1,2})|([a-zA-Z0-9][a-zA-Z0-9-]{1,61}[a-zA-Z0-9]))\.)+[a-zA-Z]{2,6}$/
([a-zA-Z]{1,2})-> pour n'accepter que deux caractères.([0-9]{1,2})-> pour accepter deux nombres uniquement
si quelque chose dépasse deux ([a-zA-Z0-9][a-zA-Z0-9-]{1,61}[a-zA-Z0-9]) cette regex prendra soin de cela.
Si nous voulons faire la correspondance pendant au moins une fois, + sera utilisé.